

Contents
はじめに:Rでデータ整理をスムーズに
臨床研究において、データ分析は非常に重要なステップです。しかし、分析の前には必ずデータの整理が必要になります。Rは、このデータ整理を効率的に行うための強力なツールです。この記事では、Rを使ってデータを読み込み、加工し、必要な形に整える基本的な方法を解説します。
「Rって難しそう…」と感じる方もいるかもしれませんが、心配はいりません。この記事では、プログラミングの経験がない方でも理解できるように、丁寧に解説していきます。Rの基礎をしっかり身につけて、データ整理のスキルを向上させましょう。
Rの便利機能:パッケージの導入
Rには、様々な便利な機能がまとまった「パッケージ」というものが存在します。今回は、データ整理に特化したtidyverseというパッケージを使います。
パッケージのインストール
tidyverse パッケージをインストールするには、以下のコードをRで実行します。
install.packages("tidyverse")
インストールは最初の1回だけでOKです。Rを起動するたびに行う必要はありません。
パッケージの読み込み
インストールしたパッケージを使うには、library() というコマンドを使います。これは、Rを起動するたびに実行する必要があります。
library(tidyverse)
このコードを実行すると、tidyverse パッケージに含まれる便利な関数が使えるようになります。
ディレクトリ構造と作業フォルダ
Rでデータを読み込む前に、少しだけ「ディレクトリ構造」について理解しておきましょう。コンピュータの中には、ファイルやフォルダが階層的に整理されています。この階層構造を「ディレクトリ構造」と呼びます。
Rは、デフォルトで「作業フォルダ」と呼ばれる特定の場所でファイルを探したり、保存したりします。read.csv() 関数でファイルを読み込む際は、この作業フォルダにファイルが保存されていればファイル名を指定するだけで読み込めます。
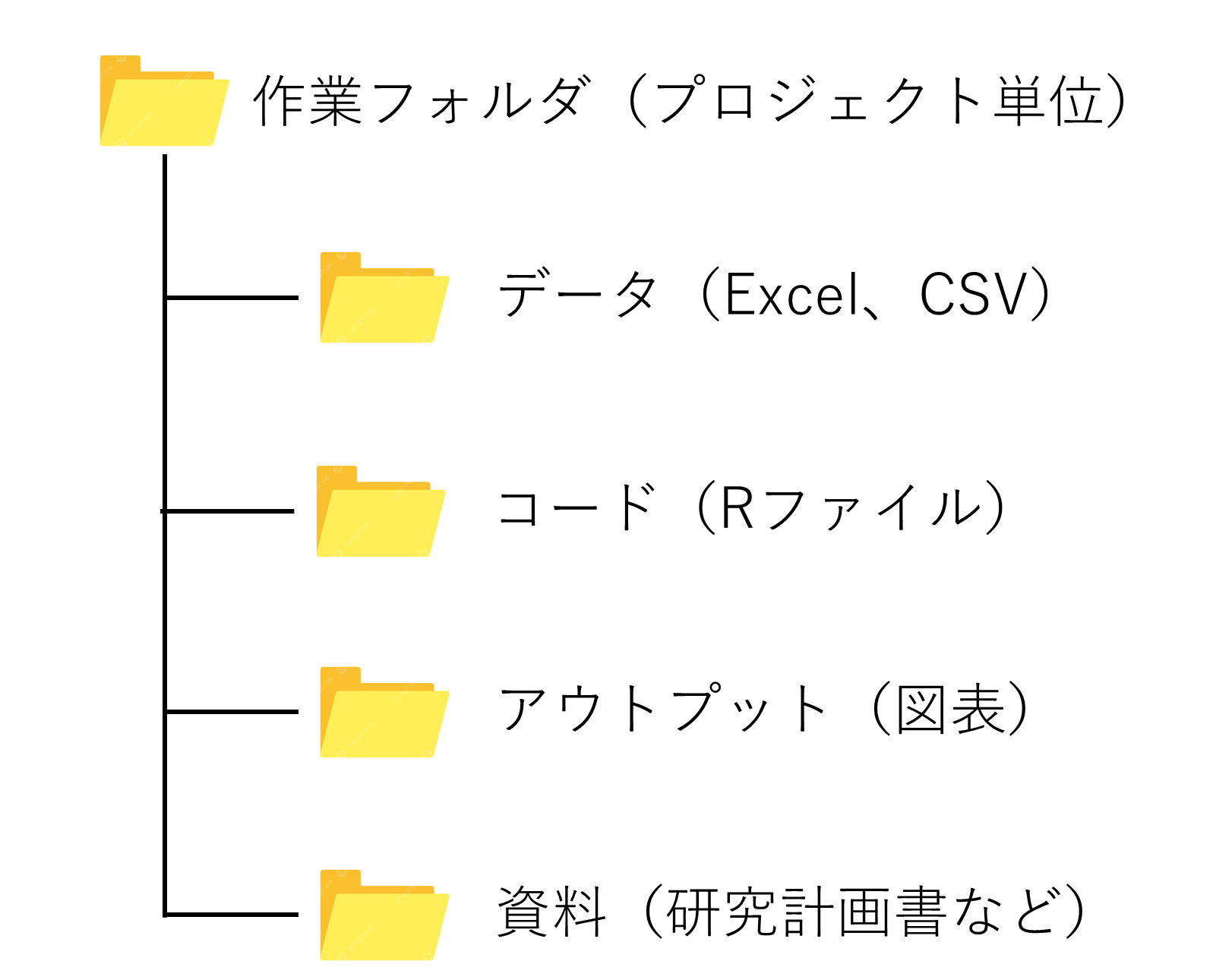
一方で、慣れきたらコードを書くRファイルや患者データファイルや出力したFigureのデータなどが同じフォルダに入っていると煩雑なので、下図のようなディレクトリ構造に整理することをおススメします。
データの読み込み:read.csv() 関数
データ整理の第一歩は、データの読み込みです。read.csv() 関数を使うと、CSV形式のファイルをRに読み込むことができます。
作業フォルダにデータがある場合
まず、読み込みたいCSVファイルをRの作業フォルダに保存します。ここでは、mydata.csv というファイル名で保存したと仮定します。
data <- read.csv("mydata.csv", na.strings = c("", "-", "NA"), fileEncoding = "SJIS")
このコードでは、
"mydata.csv"で、ファイル名を直接指定して、CSVファイルを読み込んでいます。na.strings = c("", "-", "NA")は、空白、ハイフン、NAという文字列を欠損値として扱うように指定しています。fileEncoding = "SJIS"は、日本語が含まれるファイルを正しく読み込むための設定です。他にも代表的なものとしてUTF-8があります。読み込むデータのエンコーディングに対応させるようにしてください。
読み込んだデータは、data という変数に格納されます。data はdfでもdでも好みの名前にしてください。
作業フォルダ以外にデータがある場合
もし、データが作業フォルダ以外の場所にある場合は、ファイルの場所を明示的に指定する必要があります。例えば、作業フォルダの直下に「Data」というフォルダがあり、その中に mydata.csv が保存されている場合は、以下のように記述します。
data <- read.csv("Data/mydata.csv", na.strings = c("", "-", "NA"), fileEncoding = "SJIS")
このように、フォルダ名とファイル名を / で区切って記述します。
データ整理の基本:dplyr パッケージ
Rのdplyr パッケージを使うと、データの整理がとても簡単になります。dplyr パッケージは、tidyverse パッケージをインストールすると自動的に使えるようになります。
データ処理のルール:パイプ演算子 %>%
dplyr パッケージでは、データ処理を連鎖的に行う際に「パイプ演算子 %>% 」を使います。パイプ演算子は、よく使うのでキーボードショートカットを設定しておくと便利です(RstudioではCtrl + Shift + M (macOSの場合は Cmd + Shift + M)に設定されています)。
パイプ演算子を使うことで、コードが非常に読みやすくなります。
列(変数)の追加:mutate() 関数
mutate() 関数を使うと、新しい列(変数)を追加することができます。
data <- data %>%
mutate(age_plus_10 = age + 10)
このコードでは、age 列に10を加えた値を age_plus_10 という新しい列として追加しています。
条件に応じて値を変更したい場合は、ifelse() 関数を使います。
data <- data %>%
mutate(is_adult = ifelse(age >= 20, "adult", "child"))
このコードでは、age が20以上であれば "adult"、そうでなければ "child" という値を is_adult という新しい列として追加しています。
行の抽出:filter() 関数
filter() 関数を使うと、条件に合致する行だけを抽出できます。
data_adult <- data %>%
filter(is_adult == "adult")
このコードでは、is_adult 列が "adult" である行だけを抽出しています。
列(変数)の絞り込み:select() 関数
select() 関数を使うと、必要な列(変数)だけを選択できます。
data_selected <- data %>%
select(id, age, is_adult)
このコードでは、id、age、is_adult の3つの列だけを選択しています。
並べ替え:arrange() 関数
arrange() 関数を使うと、データを特定の列(変数)の値で並べ替えることができます。
data_sorted <- data %>%
arrange(age)
このコードでは、age 列の値でデータを昇順に並べ替えています。降順に並べ替えたい場合は、desc() 関数を使います。
data_sorted <- data %>%
arrange(desc(age))
複数の処理を組み合わせる
これらの処理を組み合わせることで、より複雑なデータ整理を行うことができます。パイプ演算子 %>% を使うと、処理を連鎖的に繋げることができます。
new_data <- data %>%
mutate(age_plus_10 = age + 10,
is_adult = ifelse(age >= 20, "adult", "child")) %>%
filter(is_adult == "adult") %>%
select(id, age, age_plus_10) %>%
arrange(desc(age))
このコードでは、
ageに10を加えたage_plus_10列と、is_adult列を作成is_adultが"adult"である行を抽出id、age、age_plus_10列を選択ageの降順で並べ替え
を行っています。
おわりに
この記事では、Rを使ったデータ整理の基礎について解説しました。tidyverse パッケージや dplyr パッケージの関数を使いこなすことで、データを効率的に整理し、分析の準備をスムーズに進めることができます。今回学んだ内容を参考に、Rを使ったデータ整理にチャレンジしてみてください。

