この記事でできること
この記事では、CursorというAIエディタを使ってRを動かし、2変数間の相関係数を評価します。最終的には、一切コードを書かずにAIへの指示のみで、相関係数の算出、可視化、そしてその解釈まで行えるようになることを目指します。
AIエディタを使えば、AIに指示するだけでゼロから解析を完遂できます。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。

相関係数の分析手順
本記事の解析環境
AIエディタ: Cursor (Version 0.44.8) モデル: gemini-2.0-flash-exp
分析ステップ
- データセットの準備
- データの可視化
- 相関係数の算出
- p値の計算
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。
それでは、早速分析を始めましょう。
1. データセットの準備
今回は、Rに標準で付属しているpalmerpenguinsパッケージのpenguinsデータセットを使用します。このデータセットには、ペンギンの身体測定データが含まれており、変数間の相関を評価するのに適しています。
(Ctrl+K) palmerpenguinsパッケージのpenguinsデータを読み込んで、dfという名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(palmerpenguins)
df <- penguins
| 変数名 | 説明 |
species |
ペンギンの種(アデリー、ヒゲペンギン、ジェンツー) |
island |
ペンギンが観測された島(ビスコー、ドリーム、トーガーセン) |
bill_length_mm |
くちばしの長さ (mm) |
bill_depth_mm |
くちばしの深さ (mm) |
flipper_length_mm |
翼の長さ (mm) |
body_mass_g |
体重 (g) |
sex |
ペンギンの性別(メス、オス) |
year |
観測年 (2007, 2008, 2009) |
2. データの可視化
ここで、2変数の散布図と回帰直線のグラフを描いてみましょう
(Ctrl+K) 散布図と回帰直線のグラフを作成し、画像として保存してください。
png("scatter_plot.png")
plot(df$flipper_length_mm, df$body_mass_g,
xlab = "Flipper Length (mm)",
ylab = "Body Mass (g)",
main = "Scatter Plot of Flipper Length vs Body Mass")
abline(lm(df$body_mass_g ~ df$flipper_length_mm), col = "red")
dev.off()
作業フォルダに保存されたグラフを確認してみましょう。
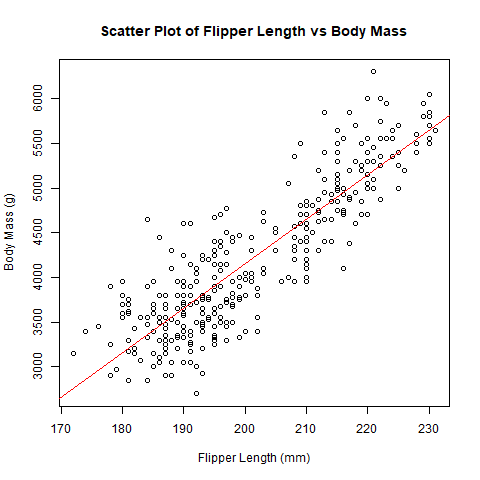
ペンギンの翼の長さと体重との関係が、散布図と回帰直線で表現されています。
3. ピアソンの相関係数とスピアマンの順位相関係数
ピアソンの相関係数
相関係数は、2つの変数の関係性の強さを-1から1の間の値で表します。1に近いほど正の相関が強く、-1に近いほど負の相関が強いことを示します。0に近い場合は、相関が弱いことを意味します。
最も一般的な相関係数はピアソンの相関係数です。これは、2つの変数が直線的な関係にある場合に特に有効で、2変数が正規分布に従うことを前提としています。
(Ctrl+K) flipper_length_mmとbody_mass_gのピアソンの相関係数を計算してください。
cor(df$flipper_length_mm, df$body_mass_g, use = "complete.obs")
use引数は、欠損値の扱い方を指定します。complete.obsは、欠損値を含む行を計算から除外する方法です。以下に、他のオプションも含めて説明します。
"everything"- データペアに一つでも欠損値が含まれる場合、結果は
NAになります。 - 最も厳格な方法で、少しでも欠損値があると計算結果が得られません。
- データペアに一つでも欠損値が含まれる場合、結果は
"all.obs""everything"と同じ動作をします。- 古いRバージョンでは違いがありましたが、現在は同じ意味です。
"complete.obs"- すべての変数で欠損値がない行のみを使用して計算します。
- 欠損値がある行は計算から除外されます。
"na.or.complete"- 少なくとも1組でも完全なデータペアがあれば、そのペアを使って計算します。
- 完全なペアがない場合は、結果は
NAになります。
"pairwise.complete.obs"- 変数ペアごとに、両方に欠損値がない観測値のみを使用します。
- 欠損値が多いデータでも、可能な限り多くの情報を使用できます。
使い分けのポイント
"everything"/"all.obs": 欠損値がほとんどない場合に適しています。"complete.obs": 計算結果は安定しますが、欠損値が多いとデータが大幅に減少します。"na.or.complete": 可能な限り計算結果を残したい場合に有効です。"pairwise.complete.obs": 欠損値が多い場合に有効ですが、結果の解釈には注意が必要です。
[1] 0.8712018
相関係数0.87は、flipper_length_mmとbody_mass_gの間に強い正の相関があることを示唆しています。
スピアマンンの順位相関係数
ピアソンの相関係数は、2変数が共に正規分布に従うことが前提となります。しかし、変数によっては外れ値があったり、正規分布に従わない場合があります。
そこで、すべてのデータを順位に変換し、順位データに対してピアソンの相関係数を算出する方法がスピアマンの順位相関係数です。
スピアマンの相関係数は、変数が正規分布に従わない場合や、外れ値の影響を軽減したい場合に適しています。
(Ctrl+K)flipper_length_mmとbody_mass_gのスピアマンの相関係数を計算してください。
cor(df$flipper_length_mm, df$body_mass_g, use = "complete.obs", method = "spearman")
[1] 0.8399741
ピアソンの相関係数とスピアマンの相関係数は、どちらも似たような結果を示しました。
4. p値の計算
相関係数の有意性を評価するために、p値を計算します。p値は、2つの変数が実際には無相関である(相関係数が0である)という帰無仮説が正しい場合に、観測されたデータ(またはそれ以上に極端なデータ)が得られる確率を示します。
(Ctrl+K) ピアソンの相関係数とスピアマンの相関係数それぞれについて、p値を計算してください。
cor.test(df$flipper_length_mm, df$body_mass_g, method = "pearson")
cor.test(df$flipper_length_mm, df$body_mass_g, method = "spearman")
Pearson's product-moment correlation
data: df$flipper_length_mm and df$body_mass_g
t = 32.722, df = 340, `p-value < 2.2e-16`
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
`0.843041 0.894599`
sample estimates:
cor
0.8712018
Spearman's rank correlation rho
data: df$flipper_length_mm and df$body_mass_g
S = 1066875, `p-value < 2.2e-16`
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.8399741
Warning message:
In cor.test.default(df$flipper_length_mm, df$body_mass_g, method = "spearman") :
Cannot compute exact p-value with ties
p値はどちらの手法でもp-value < 2.2e-16と非常に小さく、これは2つの変数の間に有意な相関があることを示しています。