

この記事を読んでできること
この記事では、CursorというAIエディタを使ってRを動かし、線形回帰分析を行います。具体的な目標地点として、一切コードを書かずにAIに指示するだけで下記のようなTableやFigureを作成します。
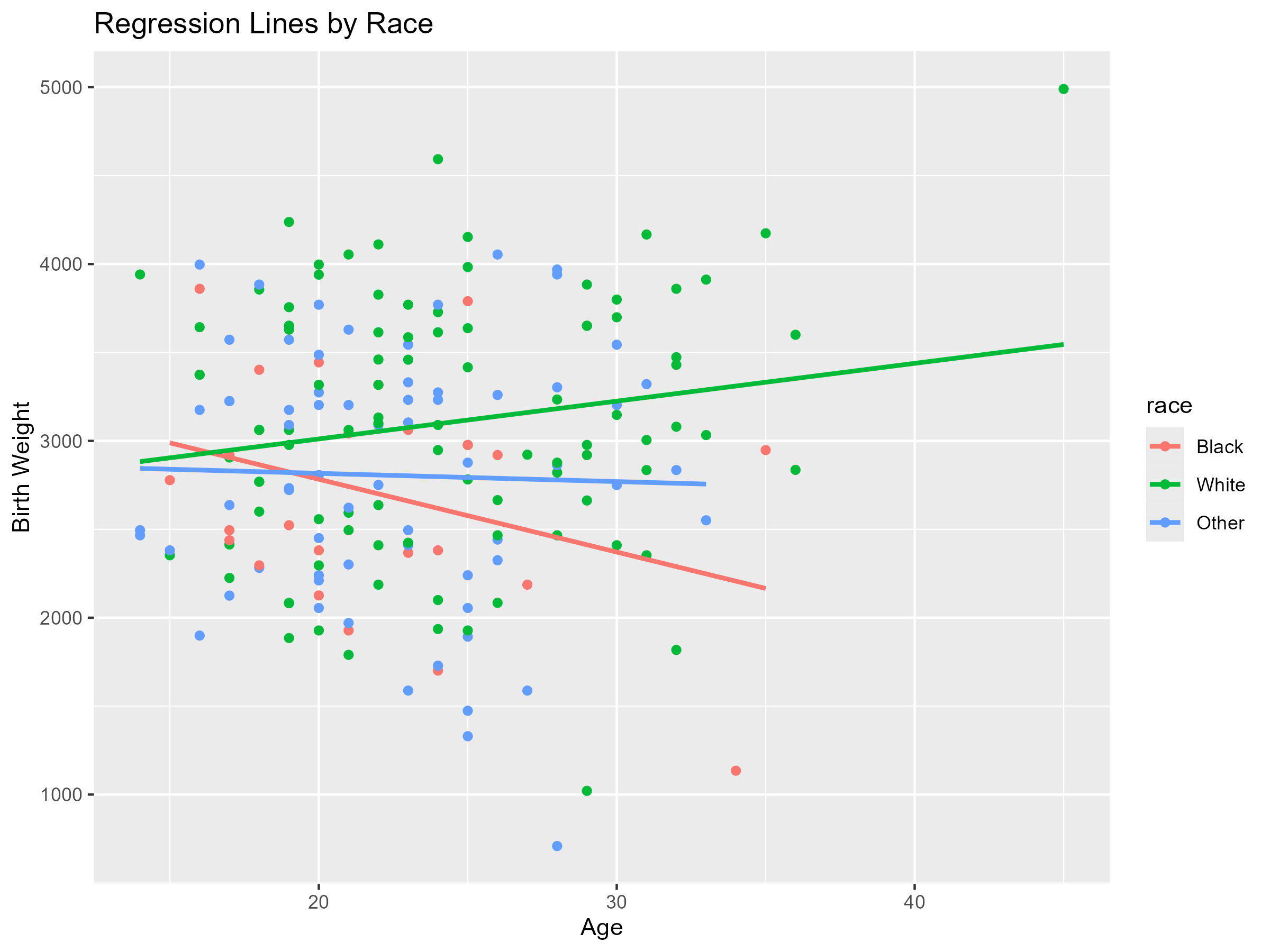
AIエディタを使えば、AIと会話するだけで全ての解析が完了し、綺麗なTableやFigureが完成します。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。
線形回帰モデルを用いた分析手順
本記事の解析環境
AIエディタ: Cursor (Version 0.44.8) モデル: gemini-2.0-flash-exp
以下のステップで分析を進めていきます。
- データセットの準備:
birthwtデータセットを読み込み、データの構造を確認します。 - 線形回帰モデルの構築: 出生時体重(
bwt)を目的変数、母親の年齢(age)と人種(race)を説明変数として線形回帰モデルを作成します。 - 解析結果のサマリを作成: 回帰係数、信頼区間、p値を算出し、解析結果を解釈します。
- カテゴリ変数の扱い: 人種(
race)のようなカテゴリ変数を適切に処理する方法を学びます。 - グラフの作成: 線形回帰モデルから得られた回帰直線のグラフを作成します。
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。 それでは、早速分析を始めましょう。

1. データセットの準備
今回は、Rに標準で付属しているMASSパッケージに含まれるbirthwtデータセットを用いて、新生児の体重(g)に影響を与える可能性のある要因を、線形回帰分析によって解析します。
(Ctrl+K) MASSパッケージのbirthwtデータを読み込んで、dfという名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(MASS)
data(birthwt)
df <- birthwt
| 変数名 | 説明 |
low |
出生時体重が2.5kg未満かどうかを示す指標(0 = 2.5kg以上、1 = 2.5kg未満) |
age |
母親の年齢(年) |
lwt |
最終月経時の母親の体重(ポンド) |
race |
母親の人種(1 = 白人、2 = 黒人、3 = その他) |
smoke |
妊娠中の喫煙状況(0 = 吸わない、1 = 吸う) |
ptl |
以前の早産の回数 |
ht |
高血圧の既往歴(0 = なし、1 = あり) |
ui |
子宮過敏性の有無(0 = なし、1 = あり) |
ftv |
妊娠初期の医師の診察回数 |
bwt |
出生時体重(グラム) |
データセットをRに読み込んだら、まず最初に行うべきことはデータの中身を確認することです。データの形式や最初の数行のデータを確認することで、データ全体の概要を把握します。
(Ctrl+K) dfのデータ形式を確認する。
str(df)
'data.frame': 189 obs. of 10 variables:
$ low : int 0 0 0 0 0 0 0 0 0 0 ...
$ age : int 19 33 20 21 18 21 22 17 29 26 ...
$ lwt : int 182 155 105 108 107 124 118 103 123 113 ...
$ race : int 2 3 1 1 1 3 1 3 1 1 ...
$ smoke: int 0 0 1 1 1 0 0 0 1 1 ...
$ ptl : int 0 0 0 0 0 0 0 0 0 0 ...
$ ht : int 0 0 0 0 0 0 0 0 0 0 ...
$ ui : int 1 0 0 1 1 0 0 0 0 0 ...
$ ftv : int 0 3 1 2 0 0 1 1 1 0 ...
$ bwt : int 2523 2551 2557 2594 2600 2622 2637 2637 2663 2665 ...
str(df)を実行することで、データフレームdfの構造を確認できます。各列(変数)の名前、データの型(数値型やカテゴリ型など)、そして最初のいくつかのデータが表示されます。intは整数データであることを示しています。これにより、データにどのような情報が含まれているかの概要を把握できます。
ここで、raceは人種(白人、黒人、その他)を表す変数であるにもかかわらず、整数型である点に注意してください。
2. 線形回帰モデルの構築
次に、線形回帰モデルを構築します。
(Ctrl+K) bwtを目的変数として、ageとraceを説明変数として線形回帰分析を行う。
model <- lm(bwt ~ age + race, data = df)
summary(model)
このRコードは線形回帰分析を実行するものです。
model <- lm(bwt ~ age + race, data = df)lm()は linear model(線形モデル)を作成する関数ですbwtが目的変数(従属変数)ですageとraceが説明変数(独立変数)ですdata = dfは使用するデータフレームを指定しています~は数式の中で「〜によって説明される」という意味を持ちます
summary(model)- 作成したモデルの詳細な統計情報を表示します
このプロンプトに従い、lm()関数を使って重回帰モデルを作成しました。bwtを目的変数とし、ageとraceを説明変数としてモデルを構築し、summary()関数でモデルの要約を確認します。
Call:
lm(formula = bwt ~ age + race, data = df)
Residuals:
Min 1Q Median 3Q Max
-2104.8 -485.7 11.3 536.0 1746.4
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3028.482 277.679 10.906 <2e-16 ***
age 8.039 10.032 0.801 0.4240
race -146.597 57.881 -2.533 0.0121 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 717.9 on 186 degrees of freedom
Multiple R-squared: 0.04122, Adjusted R-squared: 0.03091
F-statistic: 3.999 on 2 and 186 DF, p-value: 0.01994
この結果をそのまま論文で使用するには情報が多すぎるため、論文で提示するTableを作成するためにさらに加工する必要があります。
3. 解析結果のサマリー表を作成
論文で提示する解析結果のサマリーを作成するには、tbl_regression()関数が便利なので、これを使用します。
(Ctrl+K) tbl_regression関数を使用して、解析結果のサマリーを作成。
library(gtsummary)
tbl_regression(model)
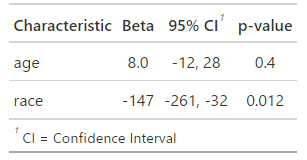
プラスの値 → 年齢が1単位増えると、結果がBeta分だけ増える(正の関連)。 マイナスの値 → 年齢が1単位増えると、結果がBeta分だけ減る(負の関連)。 例: 年齢のBetaが「8」なので、母親の年齢が1歳増えると出生時体重が8単位増える推定されています。
このような手順で、簡単に論文に提示するTableが作成できました。
4. カテゴリ変数の扱い
ここで、もともとのデータではraceは整数型で表現されており、1, 2, 3の値が順序を持つと解釈されてしまいます。実際には、raceは白人、黒人、その他の人種を表すカテゴリ変数なので、この解釈は適切ではありません。
そこで、raceをカテゴリ変数として適切に扱うために、factor()関数を使ってデータ型を変換します。これにより、raceが順序を持たないカテゴリ変数として扱われるようになります。
(Ctrl+K) raceをカテゴリ変数に変換してから、再度解析を行い、解析結果のサマリーを出力。
df$race <- factor(df$race)
model2 <- lm(bwt ~ age + race, data = df)
summary(model2)
tbl_regression(model2)
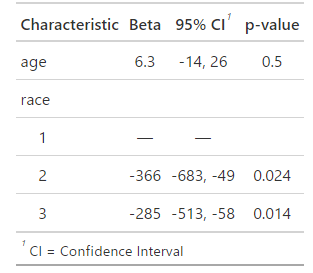
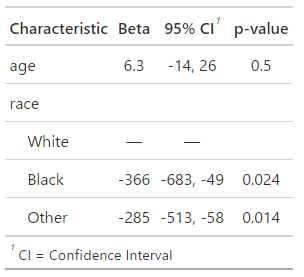
上記のプロンプトに従い、race変数がカテゴリ変数(factor型)に変換されました。結果として、race2とrace3という新しい係数が出力されました。これは、raceがカテゴリ変数として扱われたことで、それぞれのカテゴリがリファレンスカテゴリ(ここではrace1、つまり白人)と比較して、どの程度出生時体重に影響を与えているかを示すようになったからです。この結果から、黒人(race2)は白人に比べて平均して365.7グラム、その他の人種(race3)は白人に比べて平均して285.5グラム、出生時体重が低いことがわかります。
次に、この結果をさらにわかりやすくするために、raceのカテゴリにラベルを付けます。levels()関数を使って、raceの各カテゴリに "White", "Black", "Other"というラベルを付けます。
(Ctrl+K) raceに下記のラベル付けをして、同様に解析を行い、解析結果のサマリーを出力。 1:White、2:Black、3:Other
levels(df$race) <- c("White", "Black", "Other")
model3 <- lm(bwt ~ age + race, data = df)
summary(model3)
tbl_regression(model3)
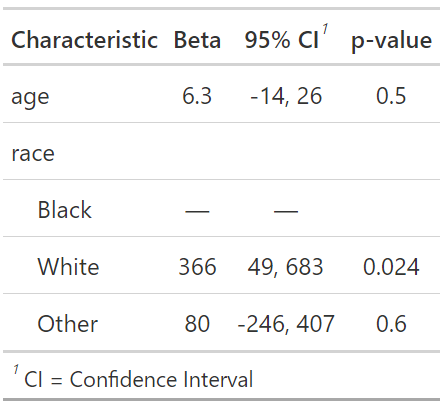
上記のプロンプトに従い、race変数にラベルを付け、再度重回帰分析を行いました。ラベル付けにより、各係数が具体的にどのグループ間の比較を示しているかが明確になりました。
次に、対照群の変更を行います。ここまでは白人を対照群にしていましたが、黒人を対照群にして同様の解析を行います。
(Ctrl+K) 対照群を"Black"に変更し、解析結果のサマリーを出力。
df$race <- factor(df$race, levels = c("Black", "White", "Other"))
model4 <- lm(bwt ~ age + race, data = df)
tbl_regression(model4)
5. グラフの作成
最後に、線形回帰モデルから得られた回帰直線をグラフにしてみましょう。
(Ctrl+K) ggplotを用いて回帰直線のグラフを作成
Rではggplot2パッケージのggplot()関数を用いてグラフを描画するのが便利です。 今回作成するグラフは、他の方法でももちろん作成可能ですが、よりフレキシブルな修正と可読性を考慮してggplotを使用するよう指示しました。
library(ggplot2)
ggplot(df, aes(x = age, y = bwt, color = race)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(title = "Regression Lines by Race",
x = "Age",
y = "Birth Weight")
作成したプロットを画像ファイルとして保存します。
(Ctrl+K) グラフを画像ファイルとして保存。
ggsave("regression_lines_by_race.png", width = 8, height = 6, units = "in")
作業フォルダに保存されたグラフを確認してみましょう。
人種ごとに、年齢と出生児体重との関係が、散布図と回帰直線で表現されています。

