


この記事を読んでできること
この記事では、CursorというAIエディタを使ってRを動かし、患者背景表を作成します。具体的な目標地点として、一切コードを書かずにAIに指示するだけで下記のような表を作成します。

AIエディタを使えば、AIと会話するだけで全ての解析が完了し、綺麗なTableやFigureが完成します。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。
コードを書かずに美しい患者背景表を作ろう!
本記事の解析環境
- AIエディタ: Cursor (Version 0.44.11)
- モデル: gemini-2.0-flash-exp
解析の手順は以下のようにすすめます。
- データセットの確認:
- 患者背景表の作成:
- 出力形式の選択:
- 患者背景表のカスタマイズ:
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。
それでは、早速分析を始めましょう。

まずはデータセットの確認
Rに標準で付属しているMASSパッケージに含まれるbirthwtデータセットを用いて患者背景表を作成します。
(Ctrl+K) ‘MASS’パッケージの’birthwt’データセットを読み込んで、’df’という名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(MASS)
df <- birthwt
| 変数名 | 説明 |
| low | 出生時体重が2.5kg未満かどうかを示す指標(0 = 2.5kg以上、1 = 2.5kg未満) |
| age | 母親の年齢(年) |
| lwt | 最終月経時の母親の体重(ポンド) |
| race | 母親の人種(1 = 白人、2 = 黒人、3 = その他) |
| smoke | 妊娠中の喫煙状況(0 = 吸わない、1 = 吸う) |
| ptl | 以前の早産の回数 |
| ht | 高血圧の既往歴(0 = なし、1 = あり) |
| ui | 子宮過敏性の有無(0 = なし、1 = あり) |
| ftv | 妊娠初期の医師の診察回数 |
| bwt | 出生時体重(グラム) |
データセットをRに読み込んだら、まず最初に行うべきことはデータの中身を確認することです。データの形式や最初の数行のデータを確認することで、データ全体の概要を把握します。
(Ctrl+K) dfのデータ形式を確認する。
str(df)
'data.frame': 189 obs. of 10 variables:
$ low : int 0 0 0 0 0 0 0 0 0 0 ...
$ age : int 19 33 20 21 18 21 22 17 29 26 ...
$ lwt : int 182 155 105 108 107 124 118 103 123 113 ...
$ race : int 2 3 1 1 1 3 1 3 1 1 ...
$ smoke: int 0 0 1 1 1 0 0 0 1 1 ...
$ ptl : int 0 0 0 0 0 0 0 0 0 0 ...
$ ht : int 0 0 0 0 0 0 0 0 0 0 ...
$ ui : int 1 0 0 1 1 0 0 0 0 0 ...
$ ftv : int 0 3 1 2 0 0 1 1 1 0 ...
$ bwt : int 2523 2551 2557 2594 2600 2622 2637 2637 2663 2665 ...
str(df)を実行することで、データフレームの構造を確認できます。各列の名前、データの型(数値型やカテゴリ型など)、そして最初のいくつかのデータが表示されます。intは整数データであることを示しています。
患者背景表の作成
早速患者背景表をつくっていきます。
母親の喫煙の有無を曝露因子とした研究を想定し、smoke列(0, 1)で群分けしてもらいます。
(Ctrl+K) tbl_summary関数を使って患者背景表を作成。 smoke列で2群に分ける
library(gtsummary)
df %>%
tbl_summary(by = smoke)
↓出力されたTable
| Characteristic | 0, N = 115 | 1, N = 74 |
| low | 29 (25%) | 30 (41%) |
| age | 23 (20, 26) | 22 (19, 26) |
| lwt | 124 (112, 142) | 120 (107, 137) |
| race | ||
| 1 | 44 (38%) | 52 (70%) |
| 2 | 16 (14%) | 10 (14%) |
| 3 | 55 (48%) | 12 (16%) |
| ptl | ||
| 0 | 103 (90%) | 56 (76%) |
| 1 | 10 (8.7%) | 14 (19%) |
| 2 | 2 (1.7%) | 3 (4.1%) |
| 3 | 0 (0%) | 1 (1.4%) |
| ht | 7 (6.1%) | 5 (6.8%) |
| ui | 15 (13%) | 13 (18%) |
| ftv | ||
| 0 | 55 (48%) | 45 (61%) |
| 1 | 35 (30%) | 12 (16%) |
| 2 | 19 (17%) | 11 (15%) |
| 3 | 3 (2.6%) | 4 (5.4%) |
| 4 | 3 (2.6%) | 1 (1.4%) |
| 6 | 0 (0%) | 1 (1.4%) |
| bwt | 3,100 (2,509, 3,622) | 2,776 (2,371, 3,246) |
最初のアウトプットとしては上々の出来にみえますが、いくつか修正したい点もあります。
- low, bwtはアウトカム(目的変数)なので背景表に含めたくない
- race, ptl, ht, uiはもともとのデータでは整数型であったが、カテゴリカル変数として扱いたい
- age, lwt, ftvは連続変数として扱いたい
そこで、先程提案されたコードを選択してCtrl+Kで追加の指示を与えます。
(Ctrl+K)
- low, bwtは項目から削除
- race, ptl, ht, uiはカテゴリカル変数として扱う
- age, lwt, ftvは連続変数として扱う
df %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{mean} ({sd})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt)
)
↓出力されたTable
| Characteristic | 0, N = 115 | 1, N = 74 |
| age | 23 (5) | 23 (5) |
| lwt | 131 (28) | 128 (34) |
| race | ||
| 1 | 44 (38%) | 52 (70%) |
| 2 | 16 (14%) | 10 (14%) |
| 3 | 55 (48%) | 12 (16%) |
| ptl | ||
| 0 | 103 (90%) | 56 (76%) |
| 1 | 10 (8.7%) | 14 (19%) |
| 2 | 2 (1.7%) | 3 (4.1%) |
| 3 | 0 (0%) | 1 (1.4%) |
| ht | ||
| 0 | 108 (94%) | 69 (93%) |
| 1 | 7 (6.1%) | 5 (6.8%) |
| ui | ||
| 0 | 100 (87%) | 61 (82%) |
| 1 | 15 (13%) | 13 (18%) |
| ftv | 1 (1) | 1 (1) |
tbl_summaryの出力タイプを選ぶ
tbl_summaryの出力形式には様々なタイプがあり、代表的なものでas_gt()、as_kable()、as_flex_table()があります。
as_gt()の出力例
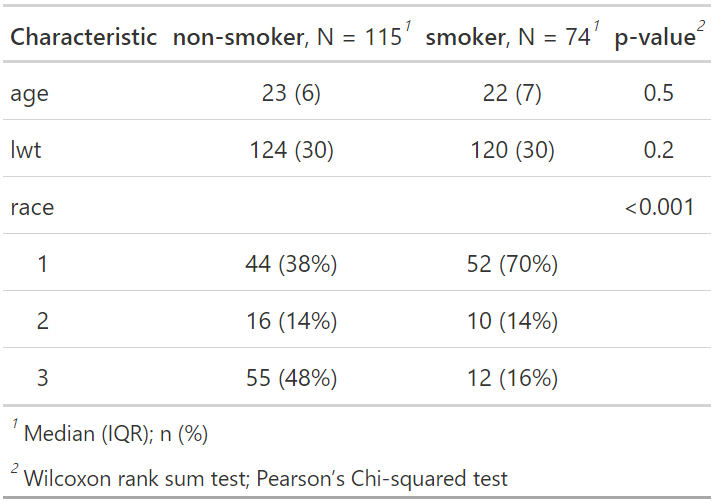
as_kable()の出力例
| Characteristic | non-smoker, N = 115 | smoker, N = 74 | p-value |
| age | 23 (6) | 22 (7) | 0.5 |
| lwt | 124 (30) | 120 (30) | 0.2 |
| race | <0.001 | ||
| 1 | 44 (38%) | 52 (70%) | |
| 2 | 16 (14%) | 10 (14%) | |
| 3 | 55 (48%) | 12 (16%) |
as_flex_table()の出力例
どれも、「as_〇〇で出力して」とAIに指示すれば変更することができます。
出力先のファイル(HTML, WORDなど)によっても見え方が若干異なるので、出力形式を複数試してみて一番の好みを探してください。
表のカスタマイズ
ここからは、好みに応じて様々な指示を出してみます。
(Ctrl+K) 全体の数を含める
df %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{median} ({IQR})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt),
) %>%
add_overall() %>%
as_kable
↓出力されたTable
| Characteristic | Overall, N = 189 | 0, N = 115 | 1, N = 74 |
| age | 23 (7) | 23 (6) | 22 (7) |
| lwt | 121 (30) | 124 (30) | 120 (30) |
| race | |||
| 1 | 96 (51%) | 44 (38%) | 52 (70%) |
| 2 | 26 (14%) | 16 (14%) | 10 (14%) |
| 3 | 67 (35%) | 55 (48%) | 12 (16%) |
| ptl | |||
| 0 | 159 (84%) | 103 (90%) | 56 (76%) |
| 1 | 24 (13%) | 10 (8.7%) | 14 (19%) |
| 2 | 5 (2.6%) | 2 (1.7%) | 3 (4.1%) |
| 3 | 1 (0.5%) | 0 (0%) | 1 (1.4%) |
| ht | |||
| 0 | 177 (94%) | 108 (94%) | 69 (93%) |
| 1 | 12 (6.3%) | 7 (6.1%) | 5 (6.8%) |
| ui | |||
| 0 | 161 (85%) | 100 (87%) | 61 (82%) |
| 1 | 28 (15%) | 15 (13%) | 13 (18%) |
| ftv | 0 (1) | 1 (1) | 0 (1) |
(Ctrl+K) 連続変数は、中央値(第1四分位数-第3四分位数)で要約
df %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{median} ({p25}-{p75})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt)
)
↓出力されたTable
| Characteristic | 0 N = 115 | 1 N = 74 |
|---|---|---|
| age | 23 (20-26) | 22 (19-26) |
| lwt | 124 (112-142) | 120 (107-138) |
| race | ||
| 1 | 44 (38%) | 52 (70%) |
| 2 | 16 (14%) | 10 (14%) |
| 3 | 55 (48%) | 12 (16%) |
| ptl | ||
| 0 | 103 (90%) | 56 (76%) |
| 1 | 10 (8.7%) | 14 (19%) |
| 2 | 2 (1.7%) | 3 (4.1%) |
| 3 | 0 (0%) | 1 (1.4%) |
| ht | ||
| 0 | 108 (94%) | 69 (93%) |
| 1 | 7 (6.1%) | 5 (6.8%) |
| ui | ||
| 0 | 100 (87%) | 61 (82%) |
| 1 | 15 (13%) | 13 (18%) |
| ftv | 1 (0-1) | 0 (0-1) |
(Ctrl+K) p値を追加
df %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{median} ({IQR})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt)
) %>%
add_p() %>%
as_kable
↓出力されたTable
| Characteristic | 0, N = 115 | 1, N = 74 | p-value |
| age | 23 (6) | 22 (7) | 0.5 |
| lwt | 124 (30) | 120 (30) | 0.2 |
| race | <0.001 | ||
| 1 | 44 (38%) | 52 (70%) | |
| 2 | 16 (14%) | 10 (14%) | |
| 3 | 55 (48%) | 12 (16%) | |
| ptl | 0.036 | ||
| 0 | 103 (90%) | 56 (76%) | |
| 1 | 10 (8.7%) | 14 (19%) | |
| 2 | 2 (1.7%) | 3 (4.1%) | |
| 3 | 0 (0%) | 1 (1.4%) | |
| ht | >0.9 | ||
| 0 | 108 (94%) | 69 (93%) | |
| 1 | 7 (6.1%) | 5 (6.8%) | |
| ui | 0.4 | ||
| 0 | 100 (87%) | 61 (82%) | |
| 1 | 15 (13%) | 13 (18%) | |
| ftv | 1 (1) | 0 (1) | 0.3 |
(Ctrl+K) 欠損値を含める
df %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{median} ({IQR})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt),
missing = "always"
) %>%
add_p() %>%
as_kable
↓出力されたTable
| Characteristic | 0, N = 115 | 1, N = 74 | p-value |
| age | 23 (6) | 22 (7) | 0.5 |
| Unknown | 0 | 0 | |
| lwt | 124 (30) | 120 (30) | 0.2 |
| Unknown | 0 | 0 | |
| race | <0.001 | ||
| 1 | 44 (38%) | 52 (70%) | |
| 2 | 16 (14%) | 10 (14%) | |
| 3 | 55 (48%) | 12 (16%) | |
| Unknown | 0 | 0 | |
| ptl | 0.036 | ||
| 0 | 103 (90%) | 56 (76%) | |
| 1 | 10 (8.7%) | 14 (19%) | |
| 2 | 2 (1.7%) | 3 (4.1%) | |
| 3 | 0 (0%) | 1 (1.4%) | |
| Unknown | 0 | 0 | |
| ht | >0.9 | ||
| 0 | 108 (94%) | 69 (93%) | |
| 1 | 7 (6.1%) | 5 (6.8%) | |
| Unknown | 0 | 0 | |
| ui | 0.4 | ||
| 0 | 100 (87%) | 61 (82%) | |
| 1 | 15 (13%) | 13 (18%) | |
| Unknown | 0 | 0 | |
| ftv | 1 (1) | 0 (1) | 0.3 |
| Unknown | 0 | 0 |
(Ctrl+K) smoke`列について、0を「non-smoker」1を「smoker」としてラベル付けする。
df %>%
mutate(smoke = factor(smoke, levels = c(0, 1), labels = c("non-smoker", "smoker"))) %>%
tbl_summary(
by = smoke,
statistic = list(all_continuous() ~ "{median} ({IQR})"),
type = list(race ~ "categorical", ptl ~ "categorical", ht ~ "categorical", ui ~ "categorical",
age ~ "continuous", lwt ~ "continuous", ftv ~ "continuous"),
include = -c(low, bwt),
) %>%
add_p()
↓出力されたTable
| Characteristic | non-smoker, N = 115 | smoker, N = 74 | p-value |
| age | 23 (6) | 22 (7) | 0.5 |
| lwt | 124 (30) | 120 (30) | 0.2 |
| race | <0.001 | ||
| 1 | 44 (38%) | 52 (70%) | |
| 2 | 16 (14%) | 10 (14%) | |
| 3 | 55 (48%) | 12 (16%) | |
| ptl | 0.036 | ||
| 0 | 103 (90%) | 56 (76%) | |
| 1 | 10 (8.7%) | 14 (19%) | |
| 2 | 2 (1.7%) | 3 (4.1%) | |
| 3 | 0 (0%) | 1 (1.4%) | |
| ht | >0.9 | ||
| 0 | 108 (94%) | 69 (93%) | |
| 1 | 7 (6.1%) | 5 (6.8%) | |
| ui | 0.4 | ||
| 0 | 100 (87%) | 61 (82%) | |
| 1 | 15 (13%) | 13 (18%) | |
| ftv | 1 (1) | 0 (1) | 0.3 |

