
Contents
この記事を読んでできること
この記事では、CursorというAIエディタを用いてRを動かしてロジスティック回帰分析を行う方法をご紹介します。具体的な目標地点として、一切コードを書かずにAIに指示するだけ下記のようなTableやFigureを作成します。
AIエディタを使えば、AIと会話するだけで全ての解析が完了し、綺麗なTableやFigureが完成します。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。
ロジスティック回帰モデルを用いた分析手順
本記事の解析環境
- AIエディタ: Cursor (Version 0.45.7)
- モデル: claude-3.5-sonnet
以下のステップで分析を進めていきます。
- データセットの準備: 分析に使用する
birthwtデータセットをRに読み込み、データの内容や構造を確認します。 - ロジスティック回帰モデルの構築: 出生時の低体重(
low)を目的変数、母親の年齢(age)と人種(race)を説明変数としてロジスティック回帰モデルを作成します。 - モデルの評価: 作成したモデルから、各説明変数が目的変数に与える影響の大きさ(オッズ比)、信頼区間、p値を推定し、モデルの結果を解釈します。
- 予測値プロットの作成: ロジスティック回帰モデルから得られる、母親の年齢や人種に対する低体重の予測確率をグラフで可視化します。
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。
それでは、早速分析を始めましょう。

1. データセットの準備
今回は、Rに標準で付属しているMASSパッケージに含まれるbirthwtデータセットを用いて、新生児の低体重(出生時体重が2500グラム未満)に影響を与える可能性のある要因を、ロジスティック回帰モデルで解析します。
(Ctrl+K) MASSパッケージの`birthwt`データを読み込んで、’df’という名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(MASS)
df <- birthwt
今回は、このデータセットに含まれるlow(新生児の出生体重が2.5kg未満かどうか)を予測したい結果(目的変数)として、母親の年齢(age)と人種(race)がどのように影響するかをロジスティック回帰モデルで解析します。
| 変数名 | 説明 |
low |
出生時体重が2.5kg未満かどうかを示す指標(0 = 2.5kg以上、1 = 2.5kg未満) |
age |
母親の年齢(年) |
lwt |
最終月経時の母親の体重(ポンド) |
race |
母親の人種(1 = 白人、2 = 黒人、3 = その他) |
smoke |
妊娠中の喫煙状況(0 = 吸わない、1 = 吸う) |
ptl |
以前の早産の回数 |
ht |
高血圧の既往歴(0 = なし、1 = あり) |
ui |
子宮過敏性の有無(0 = なし、1 = あり) |
ftv |
妊娠初期の医師の診察回数 |
bwt |
出生時体重(グラム) |
まず最初に行うべきことはデータの中身を確認することです。データの形式や最初の数行のデータを確認することで、データ全体の概要を把握します。
(Ctrl+K) dfのデータ形式を確認する。
str(df)
'data.frame': 189 obs. of 10 variables:
$ low : int 0 0 0 0 0 0 0 0 0 0 ...
$ age : int 19 33 20 21 18 21 22 17 29 26 ...
$ lwt : int 182 155 105 108 107 124 118 103 123 113 ...
$ race : int 2 3 1 1 1 3 1 3 1 1 ...
$ smoke: int 0 0 1 1 1 0 0 0 1 1 ...
$ ptl : int 0 0 0 0 0 0 0 0 0 0 ...
$ ht : int 0 0 0 0 0 0 0 0 0 0 ...
$ ui : int 1 0 0 1 1 0 0 0 0 0 ...
$ ftv : int 0 3 1 2 0 0 1 1 1 0 ...
$ bwt : int 2523 2551 2557 2594 2600 2622 2637 2637 2663 2665 ...
str(df)を実行することで、データフレームdfの構造を確認できます。各列(変数)の名前、データの型(数値型やカテゴリ型など)、そして最初のいくつかのデータが表示されます。intは整数データであることを示しています。これにより、データにどのような情報が含まれているかの概要を把握できます。
ここで、raceは整数型で表現されており、1, 2, 3の値が順序を持つと解釈されてしまいます。実際には、raceは白人、黒人、その他の人種を表すカテゴリ変数なので、この解釈は適切ではありません。 そこで、raceをカテゴリ変数として適切に扱うために、factor型にデータ変換します。
(Ctrl+K) dfの"race"列をfactor型にして、下記のようにラベル付けをしてください。 1: white 2: black 3: others
df$race <- factor(df$race, levels = c(1, 2, 3), labels = c("white", "black", "other"))
これにより、raceが順序を持たないカテゴリ変数として扱われるようになります。
2. ロジスティック回帰モデルの構築
次に、ロジスティック回帰モデルを構築します。
(Ctrl+K) lowを目的変数として、ageとraceを説明変数としてロジスティック回帰分析を行う。
model <- glm(low ~ age + race, data = df, family = binomial)
summary(model)
上記のglm(low ~ age + race, data = df, family = binomial)というコードは、ロジスティック回帰分析を実行するためのRの命令です。
glm(): これは「一般化線形モデル (Generalized Linear Model)」を構築するための関数です。ロジスティック回帰はその一種であり、通常の線形回帰では扱えない、目的変数が二値データのような場合に用いられます。low ~ age + race: これはモデルの構造を定義する「式 (formula)」と呼ばれる部分です。low ~:low(出生時体重が2.5kg未満かどうか)を予測したい変数(目的変数)であることを意味します。age + race:age(母親の年齢)とrace(母親の人種)を、lowを予測するための説明変数として使用することを意味します。
data = df: 分析に使用するデータが格納されたデータフレームの名前を指定しています。ここでは、先ほど読み込んだdfを指定しています。family = binomial: モデルの種類を指定します。binomialは二値のデータを扱う場合に用いられ、ロジスティック回帰モデルを構築するために必要です。
作成したロジスティック回帰モデルの詳細な結果を確認するために、summary()関数を使用します。
Call:
glm(formula = low ~ age + race, family = binomial, data = df)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.20802 0.80227 -0.259 0.795
age -0.03951 0.03237 -1.220 0.222
raceblack 0.74525 0.47141 1.581 0.114
raceother 0.56971 0.35239 1.617 0.106
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 234.67 on 188 degrees of freedom
Residual deviance: 228.13 on 185 degrees of freedom
AIC: 236.13
Number of Fisher Scoring iterations: 4
summary(model) の出力結果には、モデルに関する様々な情報が含まれています。重要なのはCoefficientsの部分です。ここでは、各説明変数の回帰係数(Estimate)、標準誤差(Std. Error)、z値(z value)、そしてp値(Pr(>|z|))が示されています。
- 回帰係数 (
Estimate): 各説明変数が目的変数に与える影響の大きさと方向性を示します。ロジスティック回帰の場合、この値は目的変数の対数オッズの変化を表します。例えば、ageの係数が負の値であることは、年齢が上がるほど低体重の対数オッズが減少する傾向にあることを示しています。解釈しやすさの観点から、後述するようにオッズ比に変換することが一般的です。 - 標準誤差 (
Std. Error): 回帰係数の推定値のばらつき具合を示します。標準誤差が小さいほど、推定値の信頼性が高いと考えられます。 - z値 (
z value): 回帰係数が統計的に有意であるかどうかを判断するための指標です。絶対値が大きいほど、統計的に有意である可能性が高まります。 - p値 (
Pr(>|z|)): 帰無仮説(ここでは「説明変数が目的変数に影響を与えない」という仮説)が正しい場合に、観測されたデータよりも極端なデータが得られる確率を示します。一般的にp値が0.05より小さい場合、その説明変数は統計的に有意であると判断されます。
ロジスティック回帰の結果を解釈する際には、回帰係数をオッズ比に変換して解釈する方が直感的です。オッズ比は、「ある説明変数が1単位増加した場合に、目的変数が起こるオッズが何倍になるか」を示します。 ここで得られた結果をそのまま論文で使用するには情報が多すぎるため、論文で提示するTableを作成するためにさらに加工する必要があります。
3. 解析結果のサマリー表を作成
次に、論文に載せる情報としては不要なものを削った解析結果のサマリーを作成します。 回帰モデルの結果の要約にはtbl_regression()関数が便利なので、これを使用します。
(Ctrl+K) tbl_regression関数を使用して、解析結果のサマリーを作成してください。
library(gtsummary)
model %>%
tbl_regression(
exponentiate = TRUE, # オッズ比を表示
label = list(
age = "年齢",
race = "人種"
)
) %>%
add_global_p() %>% # 全体のp値を追加
bold_p()
ここでのポイントは、ロジスティック回帰の時は必ずexponentiate = TRUEとなっていることを確認してください。ここがFALSEになっているとsummary()の結果と同じく回帰係数が対数オッズの差のまま出力されるので解釈が難しくなります。
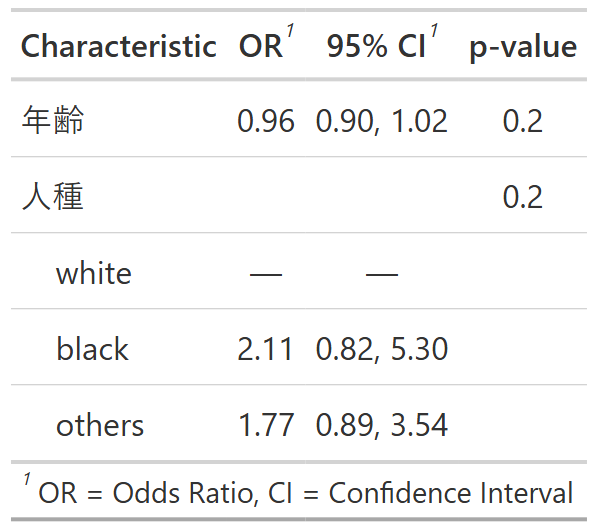
この表から、各説明変数のオッズ比、95%信頼区間、p値を読み取ることができます。
- age (母親の年齢): オッズ比は0.96となっており、母親の年齢が1歳上がるごとに、低体重のオッズが約4%減少する傾向があることを示唆しています(1 - 0.96 = 0.04)。
- white: リファレンスカテゴリ。
- black: オッズ比は2.11となっており、白人と比較して黒人の母親から生まれた子供は、低体重であるオッズが約2.11倍高い傾向があることを示唆しています。
- other: オッズ比は1.77となっており、白人と比較してその他の人種の母親から生まれた子供は、低体重であるオッズが約1.77倍高い傾向があることを示唆しています。
これで、結果の報告に適したTableが完成しました。
4. 予測値プロットの作成
ロジスティック回帰モデルから得られる、説明変数の値に応じたアウトカム発現の予測確率を可視化してみましょう。
Rでロジスティック回帰モデルの予測確率をプロットするにはrmsパッケージのPredict()関数が便利です。
(Ctrl+K) rmsパッケージのPredict関数を使ってロジスティック回帰モデルから得られる予測確率をプロットしてください。
library(rms)
# rmsのglm関数でモデルを再構築
dd <- datadist(df)
options(datadist = "dd")
model_rms <- lrm(low ~ age + race, data = df)
# 予測確率プロット作成
plot_age <- Predict(model_rms, age, fun = plogis)
plot(plot_age, ylab = "低体重児出産の予測確率", xlab = "年齢")
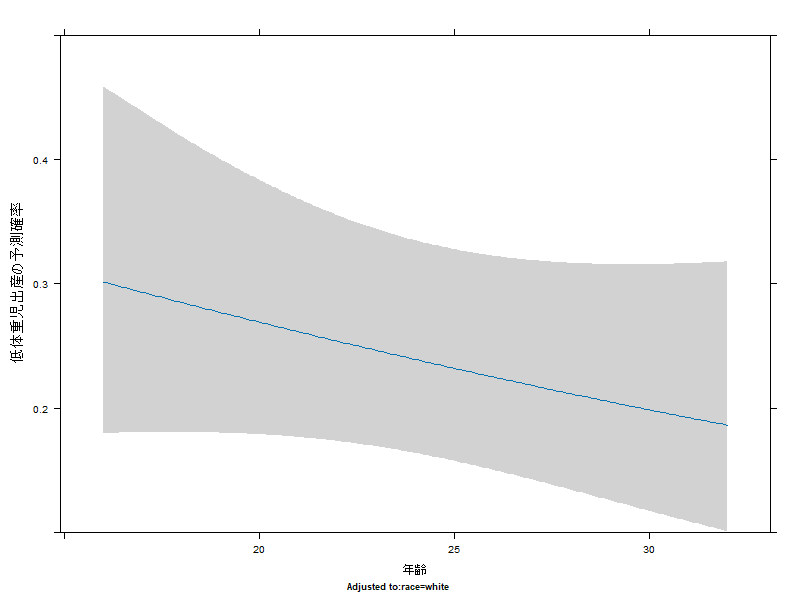
(Ctrl+K) グラフを綺麗に修正してください。
# ggplot2を使用してグラフを作成
library(ggplot2)
# 予測確率データをデータフレームに変換
plot_data <- as.data.frame(plot_age)
ggplot(plot_data, aes(x = age, y = yhat)) +
geom_line(color = "#2E86C1", size = 1) + # 線の色と太さを設定
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.2, fill = "#2E86C1") + # 信頼区間の表示
theme_minimal() + # シンプルなテーマを適用
labs(
title = "年齢と低体重児出産の予測確率の関係",
x = "年齢(歳)",
y = "低体重児出産の予測確率",
caption = "灰色の帯は95%信頼区間を示す"
) +
theme(
plot.title = element_text(size = 14, face = "bold"),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10),
legend.position = "none"
) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) # y軸をパーセント表示
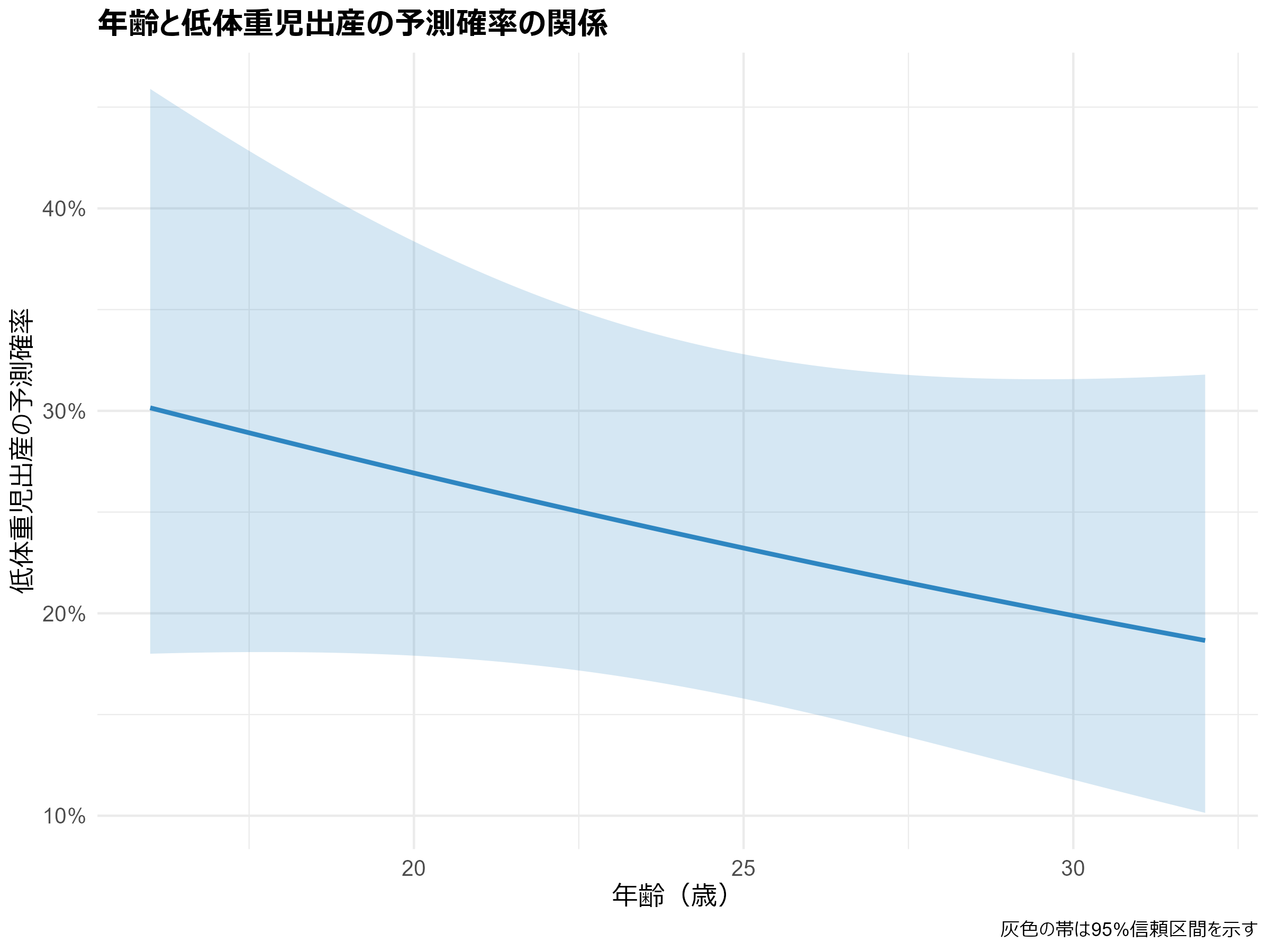
フォーマットが整えられ、見た目も綺麗になりました。
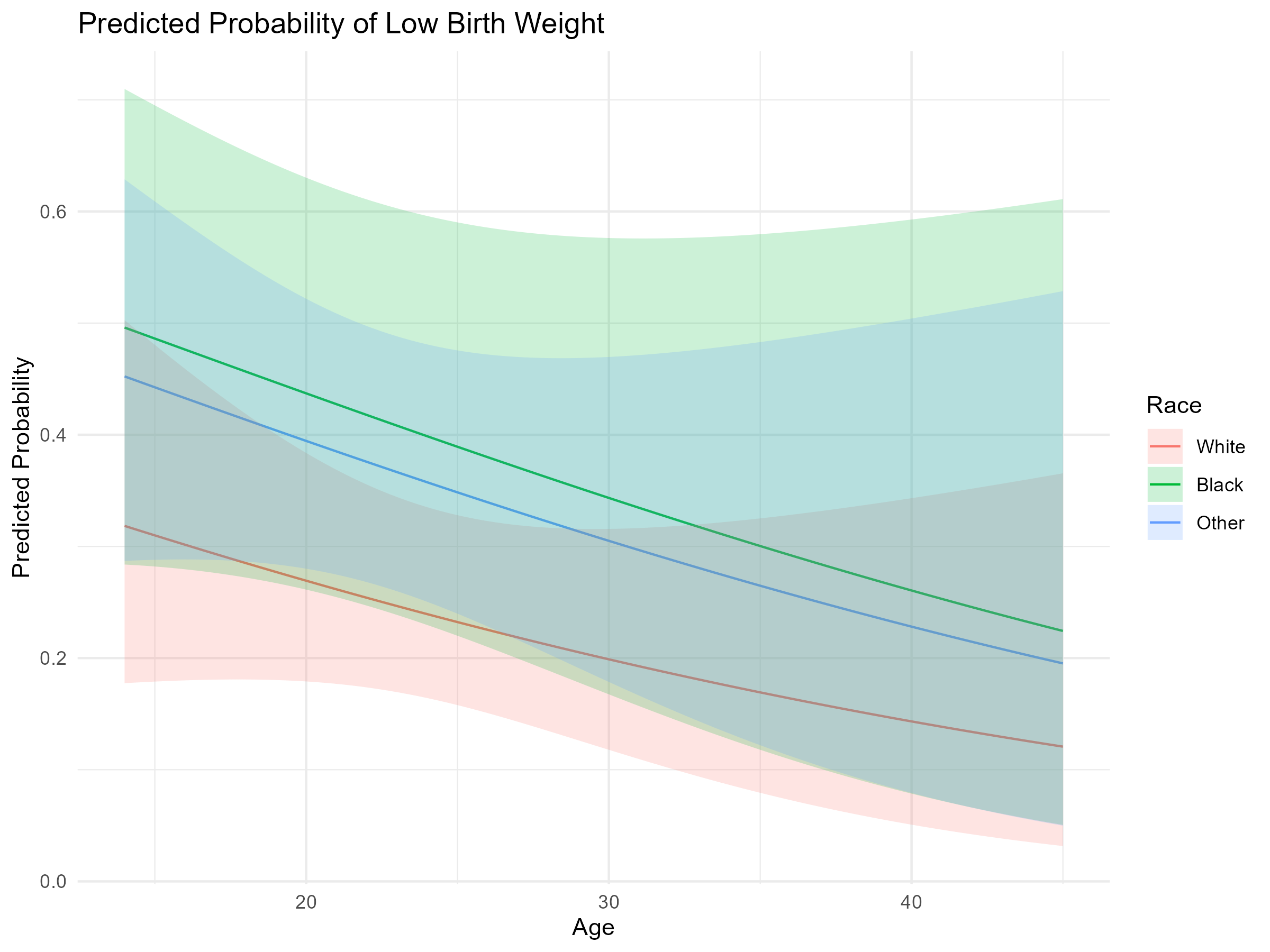
次に、人種別の予測確率をプロットします。
(Ctrl+K) raceのカテゴリごとの予測確率をプロットしてください。
plot_race <- Predict(model_rms, age, race, fun = plogis)
plot_data_race <- as.data.frame(plot_race)
ggplot(plot_data_race, aes(x = age, y = yhat, color = race, fill = race)) +
geom_line(size = 1) + # 各人種の線を描画
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.2) + # 信頼区間
theme_minimal() +
labs(
title = "年齢と人種別の低体重児出産の予測確率",
x = "年齢(歳)",
y = "低体重児出産の予測確率",
color = "人種",
fill = "人種",
caption = "色付きの帯は95%信頼区間を示す"
) +
theme(
plot.title = element_text(size = 14, face = "bold"),
axis.title = element_text(size = 12),
axis.text = element_text(size = 10)
) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_color_brewer(palette = "Set2") + # カラーパレットの設定
scale_fill_brewer(palette = "Set2")
作成したプロットを画像ファイルとして保存します。
(Ctrl+K) グラフを画像として保存。
ggsave("年齢と人種別の低体重児出産の予測確率.png", width = 10, height = 6, dpi = 300)
作業フォルダに保存されたグラフを確認してみましょう。
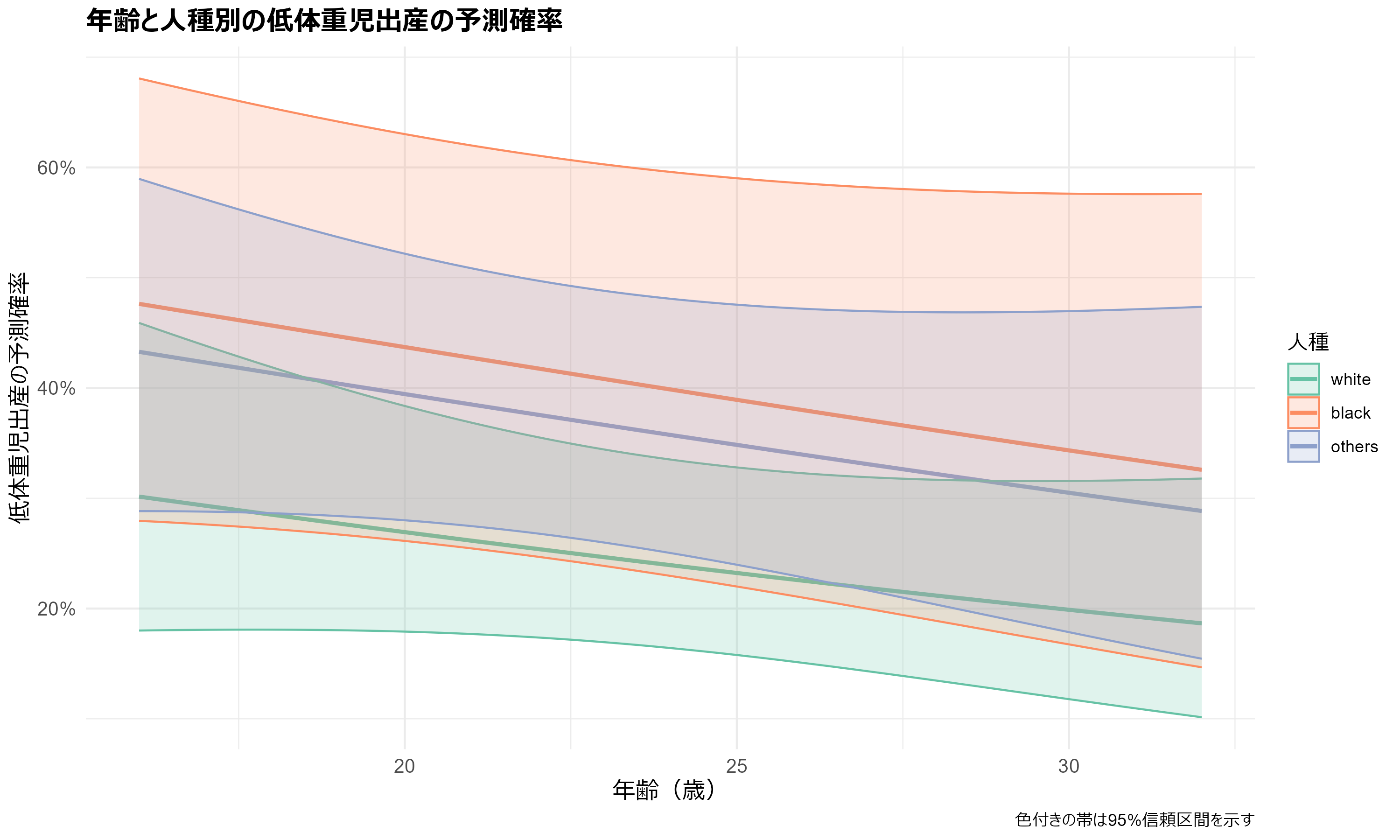
このプロットから、母親の年齢が上がるにつれて低体重の予測確率が低下する傾向が見られます。また、同じ年齢の母親であっても、人種によって低体重の予測確率が異なることが示唆されています。信頼区間の幅は、予測の不確実性を示しており、特にデータが少ない年齢層では幅が広くなっています。