

Contents
この記事では、CursorのCommand K機能 (ctrl+K) を使って、コード上からAIに指示を出してデータハンドリングを進めていきます。
この記事を読めば、データハンドリングにおけるAIへの指示の出し方が学べます。
また、臨床研究で使う場面が多い実践的なコードを扱っているので使い方を知っておくと便利です。
Cursor: 0.45.10
AIモデル: claude-3.5-sonnet
AIへの指示内容は下記のように表記して進めていきます。
データハンドリングでよく使う下記のRパッケージはあらかじめ読み込んでおきます。
library(dplyr)
library(tidyr)
library(lubridate)
library(stringr)
library(skimr)
dplyr: データフレーム操作に必要な基本的なパッケージです。tidyr: データの整形(縦長・横長変換など)を行うためのパッケージです。lubridate: 日付と時間のデータを扱うためのパッケージです。stringr: 文字列データを扱うためのパッケージです。skimr: データセットの概要統計を簡単に取得するためのパッケージです。
データの読み込み
使用するデータは、練習用に作成したサンプルデータを使用します。次の指示でGithub上のサンプルデータをdfに格納します。
(ctrl+k) https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/sample_clinical_data.csvをdfに格納
df <- read.csv("https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/sample_clinical_data.csv")
サンプルデータには下記のような変数が含まれています。
使用するデータセットについて
| 変数名 | 説明 |
| ID | (文字列): 患者固有識別子。例: PT001, PT002 |
| 年齢 | (整数): 患者の年齢(歳)。例: 60, 44 |
| 性別 | (文字列): 患者の性別。例: 女性, 男性 |
| 既往歴 | (文字列): 併存疾患のカンマ区切りリスト。例: 高血圧、糖尿病 |
| 初回来院日 | (文字列/Date): YYYY年MM月DD日形式。例: 2020年09月02日 |
| 治療レジメン | (文字列): 投与された治療法。レジメンA、レジメンB、レジメンC |
| 死亡日 | (文字列/Date): 死亡日(生存中の場合はNA)。例: 2021年06月29日 |
| マーカー_day0 | (数値): 治療開始時のマーカー値。例: 90.1 |
| マーカー_day30 | (数値): 治療30日後のマーカー値。例: 76.9 |
| マーカー_day90 | (数値): 治療90日後のマーカー値。例: 56.6 |
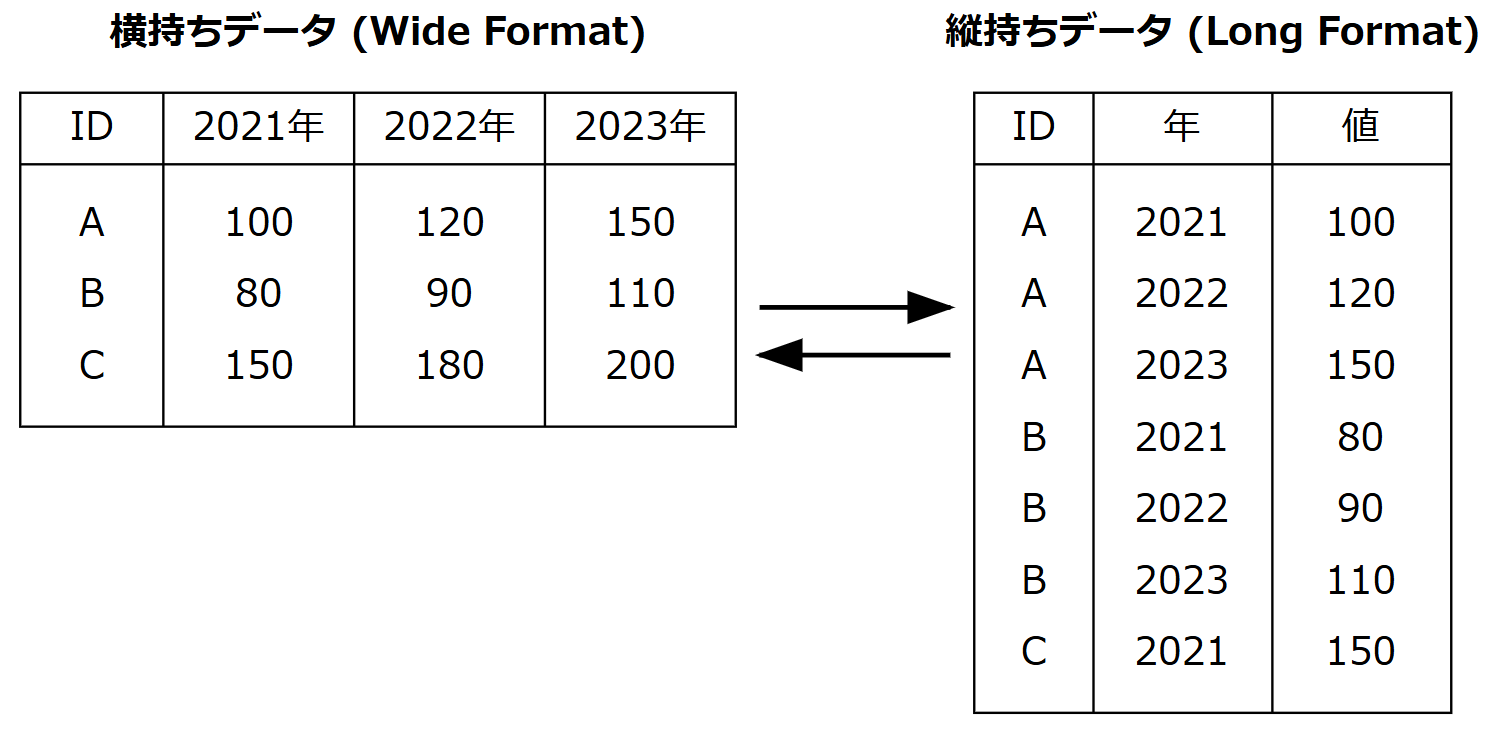
横持ちデータ・縦持ちデータ
今回は、横持ちデータ (Wide format) を扱います。横持ちデータは1症例につき1行のデータに集約されています。複数の時点のデータは異なる列に入っています。
一方で、縦持ちデータ (Long format) とは1症例のデータが複数行に分かれており、1つ1つの行には各時点のデータが入っています。
データフレームの確認
データフレームに含まれる変数のデータ型(数値型、文字列型など)や要約統計量を確認することは、データ分析の初期段階で非常に重要です。
(Ctrl+K) dfのデータ型を確認
str(df)
'data.frame': 100 obs. of 10 variables:
ID 年齢 性別 既往歴 初回来院日 治療レジメン 死亡日 測定時期 マーカー値
1 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 0 NA
2 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 30 76.9
3 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 90 56.6
4 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 0 86.8
5 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 30 98.3
6 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 90 NA
7 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 0 79.1
8 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 30 151.7
9 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 90 138.3
10 PT004 43 女性 高血圧 2020年02月17日 レジメンC 2020年11月09日 0 106.4
df の構造を表示します。各列の名前、データ型、および最初のいくつかの値を表示し、データフレームの全体像を把握するのに役立ちます。
(Ctrl+K) 列名を一覧表示
colnames(df)
[1] "ID" "年齢" "性別" "既往歴"
[5] "初回来院日" "治療レジメン" "死亡日" "マーカー_day0"
[9] "マーカー_day30" "マーカー_day90"
このコードは、colnames(df) を実行して、データフレーム df の列名(変数名)の一覧を取得し、表示します。これにより、データフレームがどのような変数を持っているかを簡単に確認できます。
(Ctrl+K) skim関数でデータを要約
skim(df)
── Data Summary ────────────────────────
Values
Name df
Number of rows 100
Number of columns 10
_______________________
Column type frequency:
character 6
numeric 4
________________________
Group variables None
── Variable type: character ────────────────────────────────────────────────────
skim_variable n_missing complete_rate min max empty n_unique whitespace
1 ID 0 1 5 5 0 100 0
2 性別 0 1 2 2 0 2 0
3 既往歴 0 1 2 11 0 16 0
4 初回来院日 0 1 11 11 0 88 0
5 治療レジメン 0 1 5 5 0 3 0
6 死亡日 70 0.3 11 11 0 30 0
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100
1 年齢 0 1 57.9 15.3 32 44 56 71 83
2 マーカー_day0 0 1 98.2 18.5 54.4 82.1 98.2 113 136.
3 マーカー_day30 0 1 78.4 19.7 26.6 64.8 78.6 89.4 152.
4 マーカー_day90 0 1 67.3 18.1 21.8 55.3 68.8 77.8 138.
hist
1 ▆▆▇▆▆
2 ▁▇▇▇▃
3 ▂▆▇▂▁
4 ▂▇▇▁▁
このコードは、skimr パッケージの skim() 関数を使用して、データフレーム df の詳細な要約統計量を計算し、表示しています。これにより、データの分布、欠損値の数、各変数の型など、データの概要を素早く把握することができます。
(Ctrl+K) 治療レジメン列のユニーク値を抽出
unique(df$治療レジメン)
[1] "レジメンA" "レジメンB" "レジメンC"
このコードは、データフレーム df の 治療レジメン 列に含まれるユニーク(一意な)な値を抽出して表示します。unique() 関数は、指定されたベクトル(ここでは df$治療レジメン 列)から重複を取り除き、ユニークな値のみを返します。これにより、治療レジメン 列にどのような治療レジメンが含まれているかを把握することができます。
ここからは、条件に合うデータを抽出したり、新たな変数を作成したり解析に必要なデータに整えていきます。
列名の変更: rename関数
データに半角括弧()やスラッシュ/が含まれていると解析で扱う際エラーが頻発します。列名に特殊な文字が含まれている場合は、rename()で変数名を変更しましょう。
(Ctrl+K) 変数名をrenameで修正
df_new <- df %>%
rename(
id = ID,
age = 年齢,
sex = 性別,
medical_history = 既往歴,
first_visit_date = 初回来院日,
treatment_regimen = 治療レジメン,
death_date = 死亡日,
marker_day0 = マーカー_day0,
marker_day30 = マーカー_day30,
marker_day90 = マーカー_day90
)
変換前のイメージ:
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー_day0 | マーカー_day30 | マーカー_day90 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 | 95 | 90 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 110 | 105 | 100 |
変換後のイメージ(df_new):
| id | age | sex | medical_history | first_visit_date | treatment_regimen | death_date | marker_day0 | marker_day30 | marker_day90 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 | 95 | 90 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 110 | 105 | 100 |
指定した列のみ名前を変更することも可能です。
rename() 関数では、新しい列名 = 古い列名 の形式で指定します。
ちなみにselect() 関数で列名を選択する時にも、新しい列名 = 古い列名 とするとselectしながら名前を変更することができるので便利です。
データの並び替え: arrange関数
(Ctrl+K) 年齢で昇順ソート
df_new <- df %>%
arrange(年齢)
このコードは、arrange() 関数を使用して、データフレーム df を 年齢 列の値に基づいて昇順に並べ替えています。
(Ctrl+K) 年齢で降順ソート
df_new <- df %>%
arrange(desc(年齢))
このコードは、arrange() 関数と desc() 関数を組み合わせて使用し、データフレーム df を年齢列の値に基づいて降順に並べ替えています。
条件に合ったデータを抽出: filter関数
(Ctrl+K) 治療レジメン列に'レジメンA'または'レジメンB'を含む行を抽出
df_new <- df %>%
filter(治療レジメン %in% c("レジメンA", "レジメンB"))
このコードは、filter() 関数を使用して、データフレーム df から特定の条件を満たす行を抽出しています。
filter(治療レジメン %in% c("レジメンA", "レジメンB")): filter() 関数の中で、治療レジメン %in% c("レジメンA", "レジメンB") という条件を指定しています。%in% は、左辺の値が右辺のベクトルに含まれているかどうかを判定する演算子です。ここでは、治療レジメン 列の値が "レジメンA" または "レジメンB" のいずれかに一致するかどうかをチェックしています。
結果として、regimen_ab_patients には、治療レジメン 列の値が "レジメンA" または "レジメンB" である行のみが含まれるようになります。
変換前のイメージ:
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 95 |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | レジメンC | NA | 90 |
| 4 | 60 | 女 | 腎臓病 | 2024-04-05 | レジメンD | NA | 85 |
変換後のイメージ(df_new):
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 95 |
列を作成・置換: mutate関数
(Ctrl+K) 治療レジメン列の値を次のように置換:
レジメンA → oxaliplatin
レジメンB → Irinotecan
レジメンC → Fluorouracil
df_new <- df %>%
mutate(治療レジメン = case_when(
治療レジメン == "レジメンA" ~ "oxaliplatin",
治療レジメン == "レジメンB" ~ "Irinotecan",
治療レジメン == "レジメンC" ~ "Fluorouracil",
TRUE ~ 治療レジメン
))
mutate(治療レジメン = ...): mutate() 関数は、データフレームに新しい列を追加したり、既存の列を修正したりするために使用されます。ここでは、既存の 治療レジメン 列を新しい値で上書きしています。
case_when(...): case_when() 関数は、複数の条件に基づいて異なる値を割り当てるための関数です。
治療レジメン == "レジメンA" ~ "oxaliplatin": もし治療レジメン列の値が"レジメンA"であれば、"oxaliplatin"に置換します。治療レジメン == "レジメンB" ~ "Irinotecan": もし治療レジメン列の値が"レジメンB"であれば、"Irinotecan"に置換します。治療レジメン == "レジメンC" ~ "Fluorouracil": もし治療レジメン列の値が"レジメンC"であれば、"Fluorouracil"に置換します。TRUE ~ 治療レジメン: 上記のいずれの条件にも当てはまらない場合(TRUEは「それ以外の場合」を意味します)、元の治療レジメンの値をそのまま使用します。
これにより、治療レジメン 列の値が指定されたルールに従って新しい値に置換されます。
変換前のイメージ:
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 95 |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | レジメンC | NA | 90 |
| 4 | 60 | 女 | 腎臓病 | 2024-04-05 | レジメンD | NA | 85 |
変換後のイメージ(df_new):
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | oxaliplatin | NA | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | Irinotecan | NA | 95 |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | Fluorouracil | NA | 90 |
| 4 | 60 | 女 | 腎臓病 | 2024-04-05 | レジメンD | NA | 85 |
作成した変数が間違ってないか確認しよう
mutateで作成した変数は必ず確認するクセをつけましょう。デフォルトではデータフレームの最終列に作成されてしまうので、確認したい変数を抜き出して別のデータフレームに入れて確認するのが手軽です。
(Ctrl+K) 年齢を65歳未満と以上に分けた変数を作成。
そのあと、新しい列と年齢のみを抜き出して先頭行を確認。
df <- df %>%
mutate(age_group = ifelse(age < 65, "Under 65", "65 or Older"))
df_subset <- df %>%
select(age_group, age)
head(df_subset)
変換前のイメージ:
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 95 |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | レジメンC | NA | 90 |
| 4 | 70 | 女 | 腎臓病 | 2024-04-05 | レジメンD | NA | 85 |
変換後のイメージ(df):
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | マーカー値 | age_group |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | レジメンA | NA | 100 | Under 65 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | レジメンB | NA | 95 | 65 or Older |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | レジメンC | NA | 90 | Under 65 |
| 4 | 70 | 女 | 腎臓病 | 2024-04-05 | レジメンD | NA | 85 | 65 or Older |
変換後のdf_subset:
| age_group | age |
| Under 65 | 50 |
| 65 or Older | 65 |
| Under 65 | 55 |
| 65 or Older | 70 |
グループごとに集計: summarise関数とgroup_by関数
(Ctrl+K) 治療レジメンごとにグループ化して平均年齢を算出
df %>%
group_by(治療レジメン) %>%
summarise(平均年齢 = mean(年齢, na.rm = TRUE))
治療レジメン 平均年齢
1 レジメンA 55.1
2 レジメンB 57.6
3 レジメンC 60.6
このコードは、治療レジメン ごとにグループ化し、各グループの平均年齢を計算しています。
df %>% group_by(治療レジメン): dplyr パッケージの group_by() 関数を使用して、治療レジメン 列の値に基づいてグループ化します。これにより、同じ治療レジメンを持つ行がグループとしてまとめられます。
summarise(平均年齢 = mean(年齢, na.rm = TRUE)): dplyr パッケージの summarise() 関数を使用して、各グループに対して要約統計量を計算します。
平均年齢 = mean(年齢, na.rm = TRUE): 平均年齢 という新しい列を作成し、その値として 年齢 列の平均値を計算します。mean() 関数は平均値を計算します。na.rm = TRUE は、欠損値 (NA) を計算から除外するオプションです。もし na.rm = FALSE (デフォルト)のままでデータに欠損値が含まれていると、結果は NA になります。
結果として、治療レジメンごとの平均年齢が計算され、治療レジメンと平均年齢からなる新しいデータフレームが出力されます。
日付データの操作
日付形式 (YYYY/MM/DDなど) のデータは少し特殊で、CSVファイルをインポートした状態では日付データはただの文字列として扱われている場合があります。
日付データが文字列として扱われていると、日付に基づいた計算やソートができません。Date型に変換することで、日付どおしの引き算で期間を計算したり、日数から月数に変換することができるようになります。
(Ctrl+K) 日付列をDate型に変換し、生存日数(死亡日 - 初回来院日)列を作成
df <- df %>%
mutate(
初回来院日 = as.Date(初回来院日, format = "%Y年%m月%d日"),
死亡日 = as.Date(死亡日, format = "%Y年%m月%d日")
)
# 生存日数を計算(死亡日がNAの場合はNA)
df <- df %>%
mutate(生存日数 = as.numeric(死亡日 - 初回来院日))
このコードは2つの操作を行っています。
日付列をDate型に変換:
as.Date()関数を使用して初回来院日列と死亡日列を日付型(Date型)に変換しています。format="%Y年%m月%d日"は、元の文字列が "YYYY年MM月DD日" という形式であることを指定しています。これにより、Rが正しく日付として認識できるようになります。
生存日数を計算:
死亡日 - 初回来院日: 日付型の列同士の引き算を行うと、期間(difftimeオブジェクト)が計算されます。as.numeric(...):as.numeric()関数で、期間を数値(日数)に変換しています。もし死亡日がNA(欠損値)の場合、計算結果もNAになります。
結果として、df には 初回来院日 と 死亡日 がDate型として格納され、新たに死亡日から初回来院日までの日数を示す生存日数 列が追加されます。
変換前のイメージ:
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 死亡日 | マーカー値 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | 2024-06-15 | 100 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | NA | 95 |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | 2024-08-20 | 90 |
| 4 | 60 | 女 | 腎臓病 | 2024-04-05 | NA | 85 |
変換後のイメージ(df):
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 死亡日 | マーカー値 | 生存日数 |
| 1 | 50 | 男 | 高血圧 | 2024-01-01 | 2024-06-15 | 100 | 165 |
| 2 | 65 | 女 | 糖尿病 | 2024-02-15 | NA | 95 | NA |
| 3 | 55 | 男 | 心疾患 | 2024-03-10 | 2024-08-20 | 90 | 163 |
| 4 | 60 | 女 | 腎臓病 | 2024-04-05 | NA | 85 | NA |
欠損値の確認
(Ctrl+K) データフレームdfの各列における欠損値の数を合計して表示
colSums(is.na(df))
ID 年齢 性別 既往歴 初回来院日
0 0 0 0 0
治療レジメン 死亡日 マーカー_day0 マーカー_day30 マーカー_day90
0 70 0 0 0
このコードは、データフレーム df の各列に含まれる欠損値 (NA) の数を列ごとに合計して表示します。
(Ctrl+K) summarise_allで全列の欠損数を一括表示
df %>%
summarise_all(~sum(is.na(.))) %>%
glimpse()
Rows: 1
Columns: 10
$ ID 0
$ 年齢 0
$ 性別 0
$ 既往歴 0
$ 初回来院日 0
$ 治療レジメン 0
$ 死亡日 70
$ マーカー_day0 0
$ マーカー_day30 0
$ マーカー_day90 0
このコードは、summarise_all() 関数と glimpse() 関数を組み合わせることで、データフレーム df の全ての列における欠損値の数を表示しています。
データの横結合:join関数
データを横に結合させたいときはjoin関数を使用します。
まず、結合する相手となるkenkoushindan.csvをweb上から読み込むために、次の指示を行います。
(Ctrl+K) https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/kenkoushindan.csvを'健診データ'に格納
健診データ <- read.csv("https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/kenkoushindan.csv")
健診データには、sample_clinical_dataの患者のうち偶数IDの患者のみが含まれていて、身長、体重、その他血液データなどが存在します。
left_join
(Ctrl+K) dfと健診データをID列をキーとしてleft_join
df_new <- df %>%
left_join(健診データ, by = "ID")
左結合 (left_join) の動作:
df(左側のデータフレーム) のすべての行は結果に含まれます。健診データ(右側のデータフレーム) のうち、dfの"ID"列の値と一致する行が結合されます。- もし
dfの行に対応する"ID"が健診データに存在しない場合、健診データから結合される列の値はNA(欠損値)となります。
結果として、df は 健診データ の情報が追加されたデータフレームに更新されます。df に元々存在した行はすべて保持され、対応する 健診データ の情報が結合されます。
変換前のイメージ:
df(元のデータ):
| ID | マーカー値 | 測定日 |
| 1 | 100 | 2024-01-01 |
| 2 | 95 | 2024-01-01 |
| 3 | 90 | 2024-01-01 |
健診データ:
| ID | 身長 | 体重 | 血圧 |
| 1 | 170 | 65 | 120 |
| 2 | 165 | 58 | 115 |
| 4 | 180 | 75 | 125 |
変換後のイメージ(df_new):
| ID | マーカー値 | 測定日 | 身長 | 体重 | 血圧 |
| 1 | 100 | 2024-01-01 | 170 | 65 | 120 |
| 2 | 95 | 2024-01-01 | 165 | 58 | 115 |
| 3 | 90 | 2024-01-01 | NA | NA | NA |
right_join
(Ctrl+K) dfと健診データをID列をキーとしてright_join
df_new <- df %>%
right_join(健診データ, by = "ID")
右結合 (right_join) の動作:
健診データ(右側のデータフレーム) のすべての行は結果に含まれます。df(左側のデータフレーム) のうち、健診データの"ID"列の値と一致する行が結合されます。- もし
健診データの行に対応する"ID"がdfに存在しない場合、dfから結合される列の値はNA(欠損値)となります。
結果として、df は 健診データ の情報が追加されたデータフレームに更新されます。健診データ に元々存在した行はすべて保持され、対応する df の情報が結合されます。
変換前のイメージ:
df(元のデータ):
| ID | マーカー値 | 測定日 |
| 1 | 100 | 2024-01-01 |
| 2 | 95 | 2024-01-01 |
| 3 | 90 | 2024-01-01 |
健診データ:
| ID | 身長 | 体重 | 血圧 |
| 1 | 170 | 65 | 120 |
| 2 | 165 | 58 | 115 |
| 4 | 180 | 75 | 125 |
変換後のイメージ(df_new):
| ID | マーカー値 | 測定日 | 身長 | 体重 | 血圧 |
| 1 | 100 | 2024-01-01 | 170 | 65 | 120 |
| 2 | 95 | 2024-01-01 | 165 | 58 | 115 |
| 4 | NA | NA | 180 | 75 | 125 |
full_join
(Ctrl+K) dfと健診データをID列をキーとしてfull_join
df_new <- df %>%
full_join(健診データ, by = "ID")
完全結合 (full_join) の動作:
df(左側のデータフレーム) と健診データ(右側のデータフレーム) のすべての行は結果に含まれます。ID列の値が一致する行同士は結合されます。- もし一方のデータフレームに行があり、他方のデータフレームに一致する
IDがない場合、対応する列の値はNA(欠損値)となります。
結果として、df は df と 健診データ のすべての情報を含むデータフレームに更新されます。両方のデータフレームのすべての行が保持され、可能な限り結合されます。
変換前のイメージ:
df(元のデータ):
| ID | マーカー値 | 測定日 |
| 1 | 100 | 2024-01-01 |
| 2 | 95 | 2024-01-01 |
| 3 | 90 | 2024-01-01 |
健診データ:
| ID | 身長 | 体重 | 血圧 |
| 1 | 170 | 65 | 120 |
| 2 | 165 | 58 | 115 |
| 4 | 180 | 75 | 125 |
変換後のイメージ(df_new):
| ID | マーカー値 | 測定日 | 身長 | 体重 | 血圧 |
| 1 | 100 | 2024-01-01 | 170 | 65 | 120 |
| 2 | 95 | 2024-01-01 | 165 | 58 | 115 |
| 3 | 90 | 2024-01-01 | NA | NA | NA |
| 4 | NA | NA | 180 | 75 | 125 |
anti_join
(Ctrl+K) dfと健診データをID列をキーとしてanti_join
df_new <- df %>%
anti_join(健診データ, by = "ID")
反結合 (anti_join) の動作:
anti_join()は、左側のデータフレーム (df) の行のうち、右側のデータフレーム (健診データ) に一致するキー(ここではID)を持たない行のみを返します。- 言い換えれば、「
dfには存在するが、健診データには対応するIDが存在しない行」を抽出します。 - 結果には、左側のデータフレームの列のみが含まれます。
結果として、df は、健診データ に対応する "ID" が存在しない df の行のみを含むデータフレームに更新されます。これは、例えば、df に含まれる患者のうち、健診データ に記録がない患者を特定する場合などに使用されます。
変換前のイメージ:
df(元のデータ):
| ID | マーカー値 | 測定日 |
| 1 | 100 | 2024-01-01 |
| 2 | 95 | 2024-01-01 |
| 3 | 90 | 2024-01-01 |
健診データ:
| ID | 身長 | 体重 | 血圧 |
| 1 | 170 | 65 | 120 |
| 2 | 165 | 58 | 115 |
| 4 | 180 | 75 | 125 |
変換後のイメージ(df_new):
| ID | マーカー値 | 測定日 |
| 3 | 90 | 2024-01-01 |
縦持ちデータ・横持ちデータへの変換
縦持ちデータへの変換: pivot_longer関数
(Ctrl+K) pivot_longer関数でマーカー列を縦持ち変換
df_long <- df %>%
pivot_longer(
cols = starts_with("マーカー"),
names_to = "測定時期",
values_to = "マーカー値"
) %>%
mutate(
測定時期 = str_replace(測定時期, "マーカー_day", "") %>% as.numeric()
)
変換前のイメージ
| 患者ID | マーカー_day0 | マーカー_day7 | マーカー_day14 |
| 1 | 100 | 95 | 90 |
| 2 | 110 | 105 | 100 |
変換後のイメージ
| 患者ID | 測定時期 | マーカー値 |
| 1 | 0 | 100 |
| 1 | 7 | 95 |
| 1 | 14 | 90 |
| 2 | 0 | 110 |
| 2 | 7 | 105 |
| 2 | 14 | 100 |
pivot_longer()の各引数の意味:
cols = starts_with("マーカー"): 変換対象の列を指定。"マーカー"で始まる列名を全て選択names_to = "測定時期": 元の列名を格納する新しい列の名前values_to = "マーカー値": 元の列の値を格納する新しい列の名前
mutate()での処理:
測定時期 = str_replace(測定時期, "マーカー_day", "") %>% as.numeric()
これは以下の操作を行っています:
str_replace(): "マーカー_day"という文字列を空文字("")に置換- 例: "マーカー_day0" → "0"
as.numeric(): 文字列を数値に変換- 例: "0" → 0
つまり、このコード全体では:
- 広い形式のデータを長い形式に変換
- 列名から不要な文字列を削除
- 測定時期を数値型に変換
という一連の操作を行っています。これにより、時系列分析などが行いやすいデータ形式に整形されます。
横持ちデータへの変換: pivot_wider関数
(Ctrl+K) pivot_wider関数でdf_longを横持ち変換
df_wide <- df_long %>%
pivot_wider(
names_from = 測定時期,
values_from = マーカー値,
names_prefix = "マーカー_day"
)
各引数の意味:
names_from = 測定時期: 新しい列名になる値が入っている列を指定します。values_from = マーカー値: 新しい列に入る値が格納されている列を指定します。names_prefix = "マーカー_day": 新しい列名の前につける接頭辞を指定します。
変換前のイメージ
| 患者ID | 測定時期 | マーカー値 |
| 1 | 0日目 | 100 |
| 1 | 7日目 | 95 |
| 1 | 14日目 | 90 |
| 2 | 0日目 | 110 |
| 2 | 7日目 | 105 |
| 2 | 14日目 | 100 |
変換後のイメージ
| 患者ID | マーカー_day0 | マーカー_day7 | マーカー_day14 |
| 1 | 100 | 95 | 90 |
| 2 | 110 | 105 | 100 |
データをCSVファイルとして出力
(Ctrl+K) df_longを縦持ちデータ.csvという名前のファイルにSJISエンコーディングで保存
write.csv(df_long, "縦持ちデータ.csv", fileEncoding = "SJIS", row.names = FALSE)
このコードは、データフレーム df_long を"縦持ちデータ.csv"という名前のCSV ファイルとして保存します。
fileEncoding = "SJIS"とすることで、ファイルに書き出す際の文字エンコーディングを "SJIS"(Shift-JIS)に指定しています。これにより、日本語環境などで文字化けを防ぐことができます。
row.names = FALSE オプションは、データフレームの行名を CSV ファイルに出力しないように指定しています。


AIへの指示内容をここに記載