

この記事では、CursorのCommand K機能 (ctrl+K) を使って、コード上からAIに指示を出してデータハンドリングを進めていきます。
この記事を読めば、データハンドリングにおけるAIへの指示の出し方が学べます。
また、臨床研究で使う場面が多い実践的なコードを扱っているので使い方を知っておくと便利です。
Cursor: 0.45.10
AIモデル: claude-3.5-sonnet
AIへの指示内容は下記のように表記して進めていきます。
データハンドリングでよく使う下記のRパッケージはあらかじめ読み込んでおきます。
library(dplyr)
library(tidyr)
dplyr: データフレーム操作に必要な基本的なパッケージです。tidyr: データの整形(縦長・横長変換など)を行うためのパッケージです。
データの読み込み
使用するデータは、練習用に作成したサンプルデータを使用します。次の指示でGithub上のサンプルデータをdfに格納します。
(ctrl+k) https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/long_format_data.csvをdfに格納
df <- read.csv("https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/long_format_data.csv")
このサンプルデータはこちらの記事で作成したデータをもとに、マーカー値の一部を欠測させたものです。
データを格納したdfには下記のような変数が含まれています。
| 変数名 | 説明 |
| ID | (文字列): 患者固有識別子。例: PT001, PT002 |
| 年齢 | (整数): 患者の年齢(歳)。例: 60, 44 |
| 性別 | (文字列): 患者の性別。例: 女性, 男性 |
| 既往歴 | (文字列): 併存疾患のカンマ区切りリスト。例: 高血圧、糖尿病 |
| 初回来院日 | (文字列/Date): YYYY年MM月DD日形式。例: 2020年09月02日 |
| 治療レジメン | (文字列): 投与された治療法。レジメンA、レジメンB、レジメンC |
| 死亡日 | (文字列/Date): 死亡日(生存中の場合はNA)。例: 2021年06月29日 |
| 測定時期 | (数値): マーカーの測定時期:0, 30, 90 |
| マーカー値 | (数値): 各測定時期におけるマーカー値。例: 76.9 |
横持ちデータ・縦持ちデータ
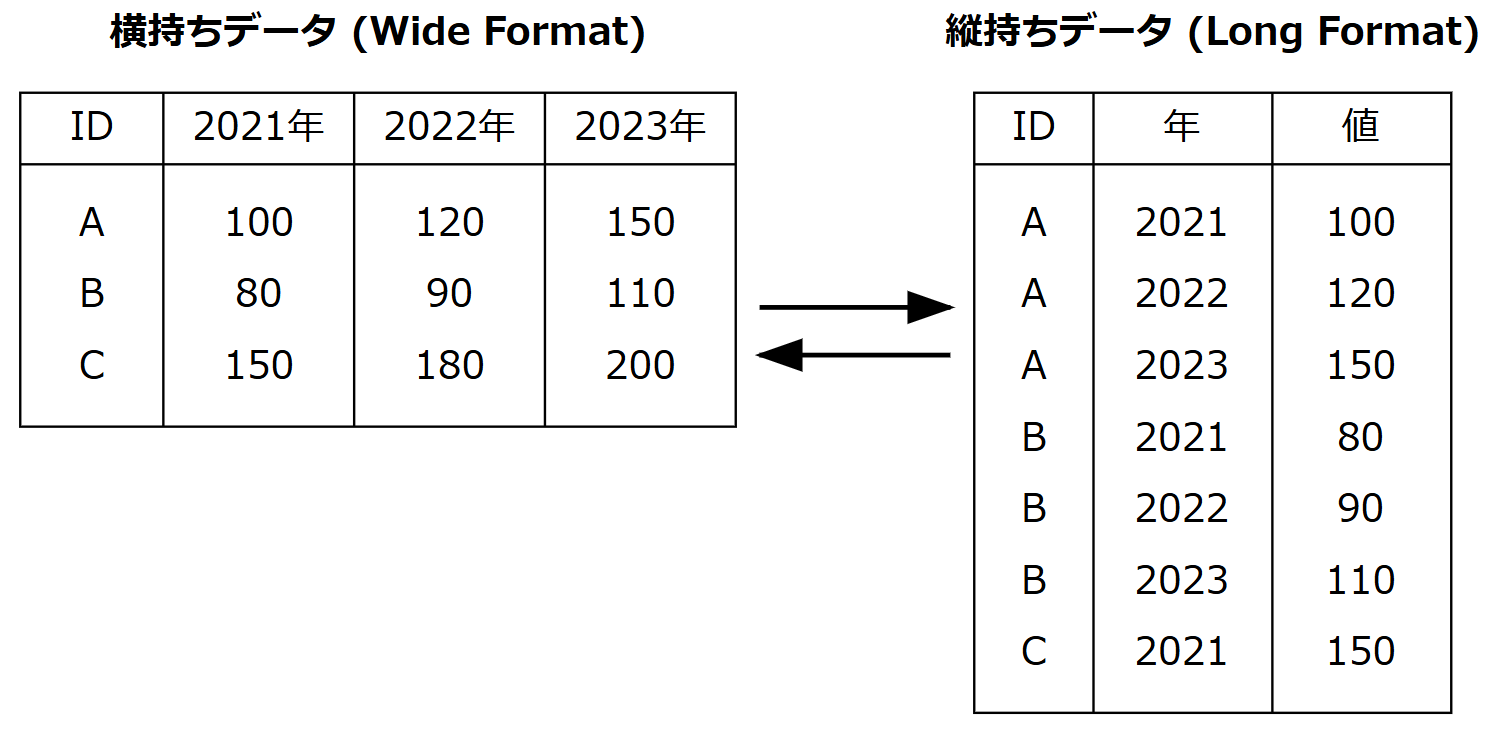
横持ちデータは1症例につき1行のデータに集約されています。複数の時点のデータは異なる列に入っています。
一方で、縦持ちデータ (Long format) とは1症例のデータが複数行に分かれており、1つ1つの行には各時点のデータが入っています。
今回は、縦持ちデータを使用します。
データフレームの確認
データを読み込んだら、まずデータ型を確認してみます。
(Ctrl+K) dfの先頭10行を確認
head(df, n=10)
ID 年齢 性別 既往歴 初回来院日 治療レジメン 死亡日 測定時期 マーカー値
1 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 0 NA
2 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 30 76.9
3 PT001 60 女性 高血圧、糖尿病、心疾患 2020年09月02日 レジメンA 90 56.6
4 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 0 86.8
5 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 30 98.3
6 PT002 44 女性 高血圧、糖尿病 2020年06月26日 レジメンA 2021年06月29日 90 NA
7 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 0 79.1
8 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 30 151.7
9 PT003 80 女性 高血圧、心疾患、糖尿病 2020年09月07日 レジメンB 90 138.3
10 PT004 43 女性 高血圧 2020年02月17日 レジメンC 2020年11月09日 0 106.4
患者ごとに行番号をふる
患者ごとに行番号をふることで、ソートしたり初回のデータを抽出するときに役立ちます。
(Ctrl+K) 患者(ID)ごとにグループ化し、行番号をふる。
df <- df %>%
group_by(ID) %>%
mutate(row_num = row_number()) %>%
ungroup()
次のような操作が行われています。
group_by(ID): データを「ID」列の値でグループ化します。以降の操作がグループごとに実行されるようになります。mutate(row_num = row_number()): 新しい列「row_num」を作成し、各グループ内で1から始まる連番を振ります。グループごとに独立して番号が振られます。ungroup(): グループ化を解除します。これにより、以降の操作は再びデータフレーム全体に対して行われるようになります。
縦持ちデータでは、患者ごとに複数行のデータが存在するので、患者ごとに操作を行う場合は忘れずにグループ化 (group_by) を行ってください。また、グループ化を行った後は忘れずにグループ解除 (ungroup) してください。
グループ化なしの場合の結果
| ID | 値 | row_num |
|---|---|---|
| A | 100 | 1 |
| A | 120 | 2 |
| A | 110 | 3 |
| B | 90 | 4 |
| B | 95 | 5 |
グループ化ありの場合の結果
| ID | 値 | row_num |
|---|---|---|
| A | 100 | 1 |
| A | 120 | 2 |
| A | 110 | 3 |
| B | 90 | 1 |
| B | 95 | 2 |
- グループ化なし:データ全体で1から連番が振られる
- グループ化あり:各IDグループ内で1から連番が振られる
累積値の計算
患者ごとにマーカー値を累積(3時点目の累積値 = 1時点目の値 + 2時点目の値 + 3時点目の値)してみましょう。
(Ctrl+K) 累積マーカー値の計算
df_new <- df %>%
group_by(ID) %>%
mutate(累積マーカー値 = cumsum(マーカー値)) %>%
ungroup()
新たに列を作成した場合はうまくいっているか確認する習慣をつけましょう。
(Ctrl+K) 作成した列を抜き出して先頭数行を確認
print(head(select(df_new, ID, マーカー値, 累積マーカー値), n=9))
ID マーカー値 累積マーカー値
1 PT001 NA NA
2 PT001 76.9 NA
3 PT001 56.6 NA
4 PT002 86.8 86.8
5 PT002 98.3 185.
6 PT002 NA NA
7 PT003 79.1 79.1
8 PT003 152. 231.
9 PT003 138. 369.
累積マーカー値がNA(欠測値)になっている箇所があります。cumsum関数で累積する際に1つでもNAがあると、以降の値が全てNAになってしまいます。
そこで、ひとまず欠測値を0に置き換えてから累積マーカー値を計算することにします。
(Ctrl+K) 欠測値を0に置き換えてから累積マーカー値を計算。
df_new <- df %>%
mutate(マーカー値= ifelse(is.na(マーカー値), 0, マーカー値))
# 患者IDごとに累積マーカー値を計算
df_new <- df_new %>%
group_by(ID) %>%
mutate(cumulative_marker = cumsum(マーカー値)) %>%
ungroup()
(Ctrl+K) 作成した列を抜き出して先頭数行を確認
print(head(select(df_new, ID, マーカー値, 累積マーカー値), n=9))
ID マーカー値 累積マーカー値
1 PT001 0 0
2 PT001 76.9 76.9
3 PT001 56.6 134.
4 PT002 86.8 86.8
5 PT002 98.3 185.
6 PT002 0 185.
7 PT003 79.1 79.1
8 PT003 152. 231.
9 PT003 138. 369.
累積マーカー値を計算することができました(欠測値はケースバイケースで適切に扱ってください)。
欠測値の補完
Last Observation Carried Forward (LOCF)
LOCFは、欠測値を前の観察値で補完する方法です。
近年は欠測値補完といえば多重補完法 (Multiple Imputation) が主流ですが、経時的なデータではLOCFが活躍する場面も多いです。
(Ctrl+K) 欠測値の補完(LOCF)
df_new <- df %>%
arrange(ID, 測定時期) %>%
group_by(ID) %>%
fill(マーカー値, .direction = "down") %>%
ungroup()
arrange(ID, 測定時期)後
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | NA |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 90 | NA |
fill(マーカー値, .direction = “down”)後の最終結果のイメージ (df_new)
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | NA |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 90 | 90 |
処理の説明:
- まず、IDと測定時期で昇順に並び替え
- グループ化(group_by)により、各ID内で独立して処理
- fill()で各グループ内のNAを、直前の値で下方向に補完
Next Observation Carried Forward (NOCF)
NOCFは、欠測値を次の観察値で補完する方法です。
(Ctrl+K) 欠測値の補完(NOCF)
df_new <- df %>%
arrange(ID, 測定時期) %>%
group_by(ID) %>%
fill(マーカー値, .direction = "up") %>%
ungroup()
arrange(ID, 測定時期) 後のイメージ
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | NA |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 90 | NA |
fill(マーカー値, .direction = “up”) 後の最終結果 (df_new)のイメージ:
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | 120 |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 90 | NA |
LOCF→NOCFの順で行って欠測値を無くしてみます。
(Ctrl+K) 欠測値の補完(LOCF→NOCF)
df_new <- df %>%
arrange(ID, 測定時期) %>%
group_by(ID) %>%
fill(マーカー値, .direction = "downup") %>%
ungroup()
fill(マーカー値, .direction = “downup”) 後の最終結果のイメージ (df_new)
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | 120 |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 90 | 90 |
fill()関数の.directionまとめ
- down: NAの値を、直前の非NAの値で下方向に埋める
- up: NAの値を、直後の非NAの値で上方向に埋める
- downup: まず下方向に埋め、残ったNAを上方向に埋める
変化量の計算 (first, last, lead, lag)
ここからは、欠損値が埋められたデータを用います。
(Ctrl+K) https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/data_long_imputed.csvをdfに格納
df <- read.csv("https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/data_long_imputed.csv")
患者ごとに最初のデータを取得: first関数
ベースライン(測定時期: 0)からのマーカー値の変化量を計算してみましょう。
(Ctrl+K) ベースラインからの変化量の計算
df_new <- df %>%
group_by(ID) %>%
mutate(ベースライン = first(マーカー値),
変化量 = マーカー値 - ベースライン) %>%
ungroup()
次のような操作が行われています。
- group_by(ID)で各患者IDごとにグループ化
- first(マーカー値)で各グループの最初のマーカー値を「ベースライン」として設定
- マーカー値 – ベースラインで各測定値からベースラインを引いて「変化量」を計算
変換前のイメージ
| ID | 来院日 | マーカー値 |
|---|---|---|
| 001 | 2024-01-01 | 100 |
| 001 | 2024-02-01 | 120 |
| 002 | 2024-01-15 | 90 |
| 002 | 2024-02-15 | 85 |
変換後のイメージ
| ID | 来院日 | マーカー値 | ベースライン | 変化量 |
|---|---|---|---|---|
| 001 | 2024-01-01 | 100 | 100 | 0 |
| 001 | 2024-02-01 | 120 | 100 | 20 |
| 002 | 2024-01-15 | 90 | 90 | 0 |
| 002 | 2024-02-15 | 85 | 90 | -5 |
患者ごとに最後のデータを取得: last関数
最終時点(測定時期: 90)からベースライン(測定時期: 0)のマーカー値の変化量を計算してみましょう。
(Ctrl+K) ベースラインから最終時点までのマーカー値の変化量を計算した列を追加。
df_new <- df %>%
group_by(ID) %>%
mutate(最終時点変化量 = last(マーカー値) - first(マーカー値)) %>%
ungroup()
変更前のイメージ
| ID | 測定時期 | マーカー値 |
|---|---|---|
| 001 | 0 | 100 |
| 001 | 30 | 120 |
| 001 | 90 | 115 |
| 002 | 0 | 90 |
| 002 | 30 | 85 |
| 002 | 90 | 82 |
変更後のイメージ
| ID | 測定時期 | マーカー値 | 最終時点変化量 |
|---|---|---|---|
| 001 | 0 | 100 | 15 |
| 001 | 30 | 120 | 15 |
| 001 | 90 | 115 | 15 |
| 002 | 0 | 90 | -8 |
| 002 | 30 | 85 | -8 |
| 002 | 90 | 82 | -8 |
次のような操作が行われています。
- group_by(ID)で各患者IDごとにグループ化
- last(マーカー値) – first(マーカー値)で90日時点の値からベースライン値を引いて最終時点変化量を計算
データを後ろにずらす: lag関数
lag関数は、1つ上の行のデータを取得します。
lag(マーカー値)とすると、1つ上の行、すなわち1つ前の時点のマーカー値を取得します。
マーカー値 – lag(マーカー値)とすると、現在の値から1つ前の値を引いた値を計算できます。
(Ctrl+K) マーカー値について、1つ前の値を引いた”Marker_diff”列を追加。
df_new <- df %>%
group_by(ID) %>%
mutate(Marker_diff = マーカー値 - lag(マーカー値)) %>%
ungroup()
変換前のイメージ
| ID | 測定時期 | マーカー値 |
|---|---|---|
| 001 | 0 | 100 |
| 001 | 30 | 120 |
| 001 | 90 | 115 |
| 002 | 0 | 90 |
| 002 | 30 | 85 |
| 002 | 90 | 82 |
変換後のイメージ
| ID | 測定時期 | マーカー値 | 前の値からの変化量 |
|---|---|---|---|
| 001 | 0 | 100 | NA |
| 001 | 30 | 120 | 20 |
| 001 | 90 | 115 | -5 |
| 002 | 0 | 90 | NA |
| 002 | 30 | 85 | -5 |
| 002 | 90 | 82 | -3 |
次のような操作が行われています。
- group_by(ID)で各患者IDごとにグループ化
- マーカー値 – lag(マーカー値)で前の値から今回の値を引いて前の値からの変化量を計算
各IDの最初の測定時点(0日目)は前の値が存在しないため、変化量はNAとなります。
データを手前にずらす: lead関数
続いて、lead関数を用いて、マーカー値の次の観察値を取得してみましょう。
(Ctrl+K) マーカー値について、次回の値から今回の値を引いた”Marker_diff”列を追加。
df_new <- df %>%
group_by(ID) %>%
mutate(Marker_diff = lead(マーカー値) - マーカー値) %>%
ungroup()
変更前のイメージ
| ID | 測定時期 | マーカー値 |
|---|---|---|
| A | 0 | 100 |
| A | 30 | 120 |
| A | 90 | 115 |
| B | 0 | 90 |
| B | 30 | 95 |
変更後のイメージ
| ID | 測定時期 | マーカー値 | 次の値からの変化量 |
|---|---|---|---|
| A | 0 | 100 | 20 |
| A | 30 | 120 | -5 |
| A | 90 | 115 | NA |
| B | 0 | 90 | 5 |
| B | 30 | 95 | NA |
次のような操作が行われています。
- group_by(ID)でIDごとにグループ化
- lead()関数で各グループ内の次の行のマーカー値を参照
- 次の値からの変化量を計算(次の値 – 現在の値)
- 最後の値は次の値が無いためNA
- ungroup()でグループ化を解除
条件を満たす最初の行を取得
filter関数とslice関数を組み合わせて、条件を満たす最初の行を取得します。
(Ctrl+K) 各患者について、マーカー値が100を超える最初のデータを取得。
df_new <- df %>%
group_by(ID) %>%
filter(マーカー値 > 100) %>%
slice(1) %>%
ungroup()
変更前のイメージ (df)
| ID | マーカー値 |
|---|---|
| A | 90 |
| A | 120 |
| A | 115 |
| B | 95 |
| B | 105 |
| B | 110 |
filter後 (マーカー値 > 100)
| ID | マーカー値 |
|---|---|
| A | 120 |
| A | 115 |
| B | 105 |
| B | 110 |
slice後 (df_new)
| ID | マーカー値 |
|---|---|
| A | 120 |
| B | 105 |
次のような操作が行われています。
- group_by(ID)でIDごとにグループ化
- filter(マーカー値 > 100)で100より大きい値のみを抽出
- slice(1)で各グループの最初の1行のみを選択
- ungroup()でグループ化を解除

AIへの指示内容をここに記載