

今回は、AIドリブンなデータハンドリングの実践テクニックとして、時系列で収集したデータから、生存時間解析用のデータセットに変換する方法をご紹介します。
使用するデータは、縦持ちデータのハンドリング記事で使用したサンプルデータです。
いきなりですが今回一番伝えたいメッセージは、「データハンドリングで何をどうすればよいか困った時はAIに質問してみよう」ということです。
具体的なAIへの指示内容は目次3つめの「AIドリブンなデータハンドリングの実践」をご覧ください。
データの準備
まずは、サンプルデータを読み込んでみましょう。
df <- read.csv("https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/long_format_data.csv")
今回は、手持ちのデータセットを使用することを想定し、あらかじめCSVファイルとして手元に保存しておきます。
(ctrl+k) dfを"long_format_data.csv"として保存
write.csv(df, "long_format_data.csv", row.names = FALSE)
保存したlong_format_data.csvは、後ほどAIに参照させるため作業用フォルダに配置しておいてください。
このサンプルデータには下記のような変数が含まれています。
| 変数名 | 説明 |
| ID | (文字列): 患者固有識別子。例: PT001, PT002 |
| 年齢 | (整数): 患者の年齢(歳)。例: 60, 44 |
| 性別 | (文字列): 患者の性別。例: 女性, 男性 |
| 既往歴 | (文字列): 併存疾患のカンマ区切りリスト。例: 高血圧、糖尿病 |
| 初回来院日 | (文字列/Date): YYYY年MM月DD日形式。例: 2020年09月02日 |
| 治療レジメン | (文字列): 投与された治療法。レジメンA、レジメンB、レジメンC |
| 死亡日 | (文字列/Date): 死亡日(生存中の場合はNA)。例: 2021年06月29日 |
| 測定時期 | (数値): マーカーの測定時期:0, 30, 90 |
| マーカー値 | (数値): 各測定時期におけるマーカー値。例: 76.9 |
実際のデータの先頭10行は下記のようになります。
| ID | 年齢 | 性別 | 既往歴 | 初回来院日 | 治療レジメン | 死亡日 | 測定時期 | マーカー値 |
|---|---|---|---|---|---|---|---|---|
| PT001 | 60 | 女性 | 高血圧、糖尿病、心疾患 | 2020年09月02日 | レジメンA | <NA> | 0 | NA |
| PT001 | 60 | 女性 | 高血圧、糖尿病、心疾患 | 2020年09月02日 | レジメンA | <NA> | 30 | 76.9 |
| PT001 | 60 | 女性 | 高血圧、糖尿病、心疾患 | 2020年09月02日 | レジメンA | <NA> | 90 | 56.6 |
| PT002 | 44 | 女性 | 高血圧、糖尿病 | 2020年06月26日 | レジメンA | 2021年06月29日 | 0 | 86.8 |
| PT002 | 44 | 女性 | 高血圧、糖尿病 | 2020年06月26日 | レジメンA | 2021年06月29日 | 30 | 98.3 |
| PT002 | 44 | 女性 | 高血圧、糖尿病 | 2020年06月26日 | レジメンA | 2021年06月29日 | 90 | NA |
| PT003 | 80 | 女性 | 高血圧、心疾患、糖尿病 | 2020年09月07日 | レジメンB | <NA> | 0 | 79.1 |
| PT003 | 80 | 女性 | 高血圧、心疾患、糖尿病 | 2020年09月07日 | レジメンB | <NA> | 30 | 151.7 |
| PT003 | 80 | 女性 | 高血圧、心疾患、糖尿病 | 2020年09月07日 | レジメンB | <NA> | 90 | 138.3 |
| PT004 | 43 | 女性 | 高血圧 | 2020年02月17日 | レジメンC | 2020年11月09日 | 0 | 106.4 |
同じ被験者について、複数の時点で取得されたデータが複数の行に格納されています。
生存時間解析用のデータフォーマットについて
ここから、生存時間解析用のデータフォーマットに変換する必要があります。
生存時間解析で必要なデータは、生存期間と、イベントの発生状況を示す変数の2つです。
具体的な手順は下記の通りです。
生存時間解析用データセット作成手順
step 1. 日付データの変換:
「初回来院日」と「死亡日」を、計算可能な日付形式(例:2020年09月02日 → 2020-09-02)に変換します。
step 2. 死亡日の確認:
死亡日の値に基づいて、イベント発生の有無を判断します。
- 死亡日が
NAの場合:生存中(打ち切りデータ) - 死亡日が存在する場合:死亡イベント発生
step 3. 生存期間(surv_time)の計算:
各患者の生存期間を日数で計算します。
- 死亡した患者:初回来院日から死亡日までの日数
- 生存中の患者:初回来院日から観察終了日までの日数
- 計算式: surv_time = 終了日 - 初回来院日
step 4. イベント発生状態(status)の決定:
イベント(死亡)の発生有無を二値変数で表現します。
- 死亡日がある患者: status = 1(イベント発生)
- 死亡日が
step 5. 最終データセットの作成:
計算したsurv_timeとstatusを元のデータに追加し、1患者1行のデータセットを作成します。
AIドリブンなデータハンドリングの実践
それでは、実際にAIに質問してみましょう。
ここでは、生存時間解析に必要なデータの形式を含めて、CursorのCHAT機能 (ctrl+L)で質問してみます。
必要なデータハンドリングの行程を教えてください。
@long_format_data.csv
正確な回答を得るために重要なのは下記の2点です。
- 1. 手持ちのデータセットの中身を理解してもらう
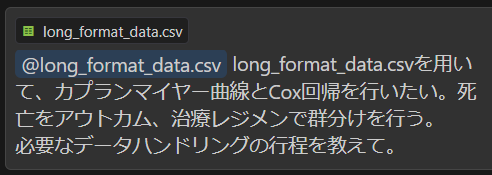
- 今回は手持ちの
long_format_data.csvを参照させます。参照機能の使い方はこちらの記事をご覧ください。 - 下記画像のように、Chat上部に
@long_format_data.csvと表示されていれば参照機能が働いています。
- 今回は手持ちの
- 2. 解析したい内容を具体的に提示する
- 具体的な解析方法(例:カプランマイヤー曲線を作成)や使用する関数名(例:coxph関数)を提示することで、AIがより的確な回答を出すことができます。
では、AIからの回答を見てみましょう。
# 必要なパッケージの読み込み
library(tidyverse)
library(survival)
library(lubridate)
library(survminer)
# データ読み込み
data <- read_csv("long_format_data.csv")
# 1. 生存時間データの作成
surv_data <- data %>%
group_by(ID) %>%
mutate(
# 日付の変換
初回来院日 = ymd(初回来院日),
死亡日 = ymd(死亡日),
# 生存時間の計算(月単位)
surv_time = ifelse(is.na(死亡日),
as.numeric(difftime(max(初回来院日 %m+% days(90)), 初回来院日, units = "days")/30),
as.numeric(difftime(死亡日, 初回来院日, units = "days")/30)),
# イベント指標(死亡=1、生存=0)
status = ifelse(is.na(死亡日), 0, 1)
) %>%
# 患者ごとに1行に集約
slice(1) %>% # 基本情報は同じなので最初の行を保持
ungroup() %>%
# 必要な列の選択
select(ID, 年齢, 性別, 既往歴, 治療レジメン, surv_time, status)
# 2. 治療レジメンで群分け
# 因子化で治療群を明確化
surv_data <- surv_data %>%
mutate(治療レジメン = factor(治療レジメン))
# 3. 共変量の前処理(例: 既往歴のダミー変数化)
surv_data <- surv_data %>%
mutate(
高血圧 = str_detect(既往歴, "高血圧") %>% as.integer(),
糖尿病 = str_detect(既往歴, "糖尿病") %>% as.integer(),
心疾患 = str_detect(既往歴, "心疾患") %>% as.integer()
)
主な処理ステップの解説:
- 日付処理: lubridateパッケージで日付を正式なDate型に変換
- 生存時間計算: 死亡日がある場合は初回来院日からの経過時間、ない場合は最終観測日(90日後)をcensoring時間として計算
- イベント指標: 死亡の有無を0/1で表現
- 治療レジメンの因子化: カテゴリカル変数として扱うため
- 既往歴の分解: 疾患の有無をダミー変数化(Cox回帰で使用可能に)
ハンドリング後のデータ
上記のコードを実行後のsurv_dataは下記のようになっています。
1回で正しく縦持ちデータから生存時間解析用のデータに変換することができました。
| ID | 年齢 | 性別 | 既往歴 | 治療レジメン | surv_time | status | 高血圧 | 糖尿病 | 心疾患 |
|---|---|---|---|---|---|---|---|---|---|
| PT001 | 60 | 女性 | 高血圧、糖尿病、心疾患 | レジメンA | 3.00 | 0 | 1 | 1 | 1 |
| PT002 | 44 | 女性 | 高血圧、糖尿病 | レジメンA | 12.30 | 1 | 1 | 1 | 0 |
| PT003 | 80 | 女性 | 高血圧、心疾患、糖尿病 | レジメンB | 3.00 | 0 | 1 | 1 | 1 |
| PT004 | 43 | 女性 | 高血圧 | レジメンC | 8.87 | 1 | 1 | 0 | 0 |
| PT005 | 32 | 男性 | なし | レジメンA | 9.57 | 1 | 0 | 0 | 0 |
| PT006 | 71 | 男性 | 高血圧、心疾患 | レジメンB | 3.00 | 0 | 1 | 0 | 1 |
| PT007 | 79 | 女性 | 心疾患 | レジメンA | 3.00 | 0 | 0 | 0 | 1 |
| PT008 | 83 | 女性 | 糖尿病 | レジメンB | 1.13 | 1 | 0 | 1 | 0 |
| PT009 | 72 | 女性 | 高血圧、心疾患 | レジメンC | 3.00 | 0 | 1 | 0 | 1 |
| PT010 | 66 | 男性 | 心疾患、糖尿病、高血圧 | レジメンB | 3.00 | 0 | 1 | 1 | 1 |
CHAT機能では、Composerで使用できない推論が得意なAiモデルを使用できるメリットがあります。
今回は推論力が高いAIモデルdeepseek-r1を使用しました。少し余談ですがCursorでAIを使用する際の情報セキュリティに関してはこちらの記事をご覧ください。

(ctrl+k) https://github.com/r-biostat/public/raw/refs/heads/main/sample_data/long_format_data.csvをdfに格納