

Contents
1. はじめに
解析手順書の作成からAIに全任せした記事では、以下のように、解析手順書の作成から解析まで全てAIに任せしました。
- 臨床課題から解析手法の提案
- 解析手順書の作成
- AIエージェントで自動解析 → 解析レポート作成
- 論文に記載するStatistical AnalysisとResultsの作成
結果として、解析を自動化できた一方、一部コードに誤りがありました。
その原因をたどると、AIが作成した解析手順書の記述があいまいだったことが主な要因でした。
そこで今回は、人間が作成した解析計画書に沿ってAIに解析してもらいます。
具体的な手順は下記の通りです。
- 解析手順書とデータ定義書を作成する
- AIエージェントに解析~レポート作成をお願いする
それでは早速、実践プロセスをみていきましょう。
2. データセットの準備
今回使用するのは、糖尿病患者の介入群と対照群についてHbA1cの推移を追跡した縦持ちデータセットです。
このデータでは、患者の来院毎に行データが存在します。
HbA1cとクレアチニン値 (CRE) は時間依存で変動し、その他の変数はベースラインから変動はありません。
先頭10行を以下に示します。
| ID | visit_date | age | sex | race | weight | height | smoke | drink | regular_exercise |
| 1 | 2020/1/14 | 64 | 1 | 2 | 93.1 | 173. | 0 | 0 | 0 |
| 2 | 2020/3/19 | 64 | 1 | 2 | 93.1 | 173. | 0 | 0 | 0 |
| 3 | 2020/7/7 | 64 | 1 | 2 | 93.1 | 173. | 0 | 0 | 0 |
| 4 | 2020/8/15 | 64 | 1 | 2 | 93.1 | 173. | 0 | 0 | 0 |
| 5 | 2020/1/22 | 60 | 2 | 1 | 68.4 | 168. | 1 | 1 | 2 |
| 6 | 2020/4/20 | 60 | 2 | 1 | 68.4 | 168. | 1 | 1 | 2 |
| 7 | 2020/8/11 | 60 | 2 | 1 | 68.4 | 168. | 1 | 1 | 2 |
| 8 | 2020/9/29 | 60 | 2 | 1 | 68.4 | 168. | 1 | 1 | 2 |
| 9 | 2020/1/9 | 54 | 1 | 2 | 77.7 | 175. | 0 | 0 | 2 |
データセットはこちらをご利用ください。
3. データ定義書の作成
続いて、AIエージェントに渡すデータ定義書を作成します。
データ定義書や解析手順書など、AIに読ませる文章はMarkdown形式で記述します。
作成したデータ定義書はこちらです。下記のように、データセットの各列について、データ型や値の範囲などを整理しています。
| 列名 | データ型 | 説明 |
|---|---|---|
| ID | 整数 | 被験者識別子 |
| visit_date | 文字列 | 受診日(YYYY-MM-DD) |
| age | 整数 | 受診時の年齢(歳) |
| sex | 整数(1: 男性, 2: 女性) | 性別(1: 男性, 2: 女性) |
| race | 整数(1: 白人, 2: 黒人, 3: その他) | 人種(1: 白人, 2: 黒人, 3: その他) |
| weight | 数値 | 体重(kg) |
| height | 数値 | 身長(cm) |
| smoke | 整数(0: 非喫煙, 1: 喫煙) | 喫煙状況(0: 非喫煙, 1: 喫煙) |
| drink | 整数(0: 飲酒なし, 1: 飲酒あり) | 飲酒状況(0: 飲酒なし, 1: 飲酒あり) |
| regular_exercise | 数値 | 定期的な運動頻度(0~3) |
| interv | 整数(0: 対照群, 1: 介入群) | 介入群識別(0: 対照群, 1: 介入群) |
| HbA1c | 数値/文字列 | HbA1c 値 |
| CRE | 数値 | クレアチニン値(mg/dL) |
4. 解析手順書の作成
一番の肝である解析手順書を作成します。こちらもMarkdown形式で作成します。
実際に使用した解析手順書はこちらで公開しています。
以下に要点を記載します。
- データハンドリング
- データの読み込み(datasheet.csv)
- 欠損値の確認・処理(HbA1cはLOCF法で補完)
visit_dateを文字列型から日付型へ変換、regular_exerciseを因子型に変換- BMI、CrCL、
event変数の作成 - 除外基準の適用 →
baselineデータの作成 event_dateデータの作成 →df_mergedに左結合
- 解析
- 患者背景表の作成
- 生存時間解析(Kaplan-Meier曲線、Cox比例ハザードモデル)
- 運動習慣レベルごとのサブグループ解析(
regular_exercise別のKaplan-Meier)
5. AIエージェントに解析してもらおう!
準備したデータセット (datasheet.csv)、解析手順書 (analysis_plan.md)、およびデータ定義書 (data_dictionary.md)を準備したら、あとはAIエージェントに渡すだけです。
今回使うCursorのAI機能はComposer (agentモード)です。
また、解析レポートを作成するためにQuartoを使用します。
5.1 ファイル生成と実行
まずは、下記のようにデータセット、解析手順書、データ定義書を参照させながらAIに指示を出します。
AIが必要なファイル(例: install_packages.R、analysis_report.qmdなど)を自動生成します。
生成したファイルが実行されます。
これで、全ての解析が完了しました。
6. データハンドリングの概要
以下に、実際に生成されたRコードと、データ変換のイメージを示します。
ステップ0:変換前のdf(例示)
| ID | visit_date | regular_exercise | sex | race | smoke | drink | interv | age | weight | height | CRE | HbA1c |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2024-05-10 | 1 | 1 | 1 | 0 | 1 | 0 | 60 | 70 | 170 | 0.9 | 6.8 |
| 1 | 2024-08-10 | 0 | 1 | 1 | 0 | 1 | 0 | 60 | 70 | 170 | 0.9 | 7.2 |
| 2 | 2024-06-01 | 1 | 2 | 3 | 1 | 0 | 1 | 55 | 65 | 160 | 1.0 | 6.5 |
—
ステップ1:データ型の変換と変数の作成
# 日付型への変換
df <- df %>%
mutate(
visit_date = ymd(visit_date),
# regular_exerciseを因子型に変換
regular_exercise = factor(regular_exercise),
# sexを因子型に変換
sex = factor(sex, levels = c(1, 2), labels = c("男性", "女性")),
# raceを因子型に変換
race = factor(race, levels = c(1, 2, 3), labels = c("白人", "黒人", "その他")),
# smoke, drinkを因子型に変換
smoke = factor(smoke, levels = c(0, 1), labels = c("非喫煙", "喫煙")),
drink = factor(drink, levels = c(0, 1), labels = c("飲酒なし", "飲酒あり")),
# intervを因子型に変換
interv = factor(interv, levels = c(0, 1), labels = c("対照群", "介入群"))
)
# BMIの計算
df <- df %>%
mutate(bmi = weight / ((height/100)^2))
# クレアチニンクリアランスの計算(Cockcroft-Gault式)
df <- df %>%
mutate(
CrCL = case_when(
sex == "男性" ~ (140 - age) * weight / (72 * CRE),
sex == "女性" ~ (140 - age) * weight / (72 * CRE) * 0.85
)
)
# 患者ごとの最初と最後のvisit_date
df <- df %>%
group_by(ID) %>%
mutate(
first_visit_date = min(visit_date),
last_visit_date = max(visit_date)
) %>%
ungroup()
# HbA1cが7以上の場合のイベント作成
df <- df %>%
mutate(event = ifelse(HbA1c >= 7, 1, 0))
以下の処理が行われています:
- visit_dateをDate型へ
- regular_exercise, sex, race, smoke, drink, intervを因子型(ラベル付き)へ変換
- bmi列を追加:
weight / ((height/100)^2) - CrCL列を追加(Cockcroft-Gault式)
- 患者ごとの最初(first_visit_date)と最後(last_visit_date)の受診日を集計
- HbA1c >= 7の場合
event = 1、それ以外は0
| ID | visit_date | regular_exercise | sex | race | smoke | drink | interv | age | weight | height | CRE | HbA1c | bmi | CrCL | first_visit_date | last_visit_date | event |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2024-05-10 | 1 (あり/なしなど) | 男性 | 白人 | 非喫煙 | 飲酒あり | 対照群 | 60 | 70 | 170 | 0.9 | 6.8 | 24.22 | (計算値) | 2024-05-10 | 2024-08-10 | 0 |
| 1 | 2024-08-10 | 0 (あり/なしなど) | 男性 | 白人 | 非喫煙 | 飲酒あり | 対照群 | 60 | 70 | 170 | 0.9 | 7.2 | 24.22 | (計算値) | 2024-05-10 | 2024-08-10 | 1 |
| 2 | 2024-06-01 | 1 (あり/なしなど) | 女性 | その他 | 喫煙 | 飲酒なし | 介入群 | 55 | 65 | 160 | 1.0 | 6.5 | 25.39 | (計算値)※性別係数0.85がかかる | 2024-06-01 | 2024-06-01 | 0 |
—
ステップ2:除外基準適用後(df_clean)
# 初回来院時のHbA1c >= 7または欠測の患者を除外
excluded_ids <- df %>%
group_by(ID) %>%
filter(visit_date == first_visit_date) %>%
filter(HbA1c >= 7 | is.na(HbA1c)) %>%
pull(ID)
df_clean <- df %>%
filter(!ID %in% excluded_ids)
初回来院時 (visit_date == first_visit_date) のHbA1cが7以上または欠測のIDを除外します。
| ID | visit_date | HbA1c | first_visit_date | last_visit_date | event |
|---|---|---|---|---|---|
| 1 | 2024-05-10 | 6.8 | 2024-05-10 | 2024-08-10 | 0 |
| 1 | 2024-08-10 | 7.2 | 2024-05-10 | 2024-08-10 | 1 |
| 2 | 2024-06-01 | 6.5 | 2024-06-01 | 2024-06-01 | 0 |
—
ステップ3:解析用データセットの作成
# baselineデータフレーム
baseline <- df_clean %>%
group_by(ID) %>%
filter(visit_date == first_visit_date) %>%
ungroup()
# event_dateデータフレーム
event_date <- df_clean %>%
group_by(ID) %>%
filter(event == 1) %>%
filter(visit_date == min(visit_date)) %>%
select(ID, visit_date, event) %>%
rename(
event_date = visit_date,
status = event
) %>%
ungroup()
# df_mergedデータフレーム
df_merged <- baseline %>%
left_join(event_date, by = "ID") %>%
mutate(
status = replace_na(status, 0),
time = case_when(
status == 0 ~ as.numeric(last_visit_date - first_visit_date),
status == 1 ~ as.numeric(event_date - first_visit_date)
)
)
① baseline
df_cleanからvisit_date == first_visit_dateの行を抽出し、ベースライン情報を取得。
| ID | visit_date | HbA1c | first_visit_date | last_visit_date |
|---|---|---|---|---|
| 1 | 2024-05-10 | 6.8 | 2024-05-10 | 2024-08-10 |
| 2 | 2024-06-01 | 6.5 | 2024-06-01 | 2024-06-01 |
② event_date
イベント(event == 1)が起きた日付を抽出し、最短の訪問日をevent_dateとしてまとめます。
| ID | event_date | status |
|---|---|---|
| 1 | 2024-08-10 | 1 |
③ df_merged
baselineにevent_dateをIDで結合し、status(イベントの有無)やtime(追跡期間)を計算して作成したデータフレーム。
| ID | visit_date (baseline) | HbA1c | first_visit_date | last_visit_date | event_date | status | time |
|---|---|---|---|---|---|---|---|
| 1 | 2024-05-10 | 6.8 | 2024-05-10 | 2024-08-10 | 2024-08-10 | 1 | 92 |
| 2 | 2024-06-01 | 6.5 | 2024-06-01 | 2024-06-01 | NA | 0 | 0 |
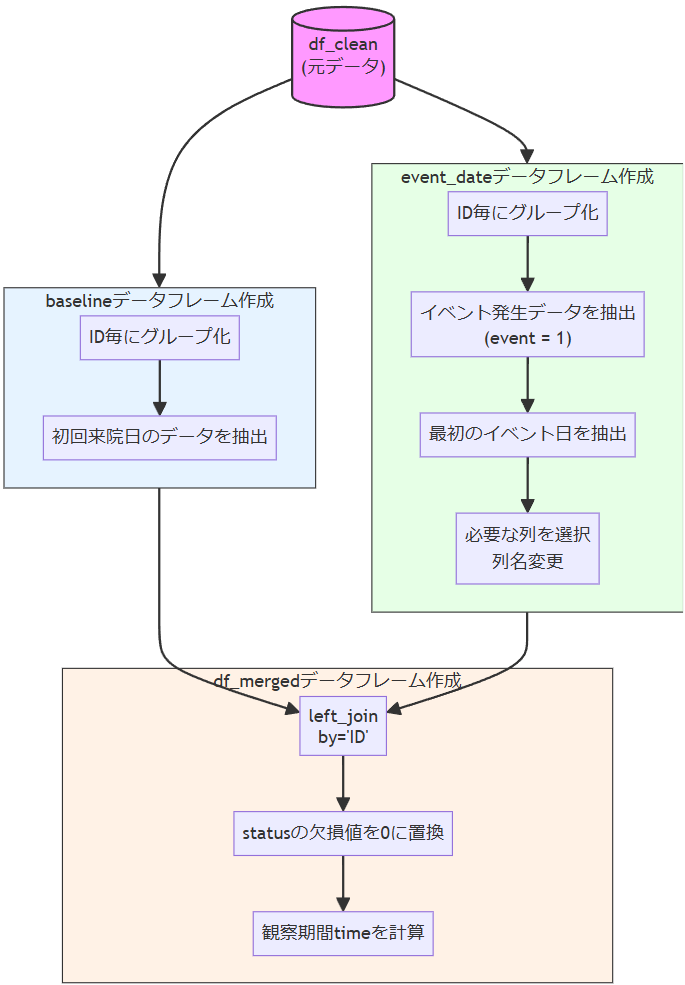
ステップ3はやや複雑で、ここまでで作成したデータから、下記2つのデータフレームを新たに作成し、最終的にマージします。
- baselineデータフレーム
- 初回来院日のデータ
- event_dateデータフレーム
- このデータには、イベントが起きた患者の、初回イベント発生日のデータが存在します。
①と②を左結合します。これにより、イベントが起きた患者にはevent_date列にイベント発生日が、status列に1(イベントありを示す)が入ります。
一方、フォローアップ最終日までイベントが起きなかった患者はNAになり、これが打ち切りで終了した目印となります。
ステップ3のイメージ
7. 解析レポートの確認
Quartoで出力された解析レポートを確認します。完成版はこちらです。
結果をざっくりとレビューしていきましょう。
データハンドリング
全体としては、手順書に沿った解析をほとんどサボらず実行してくれました。
一点残念だったのが、手順書に「HbA1c欠測値はLOCF法で補完」と明記していたにもかかわらず、AIがスキップしてしまっていました。結果に直結する部分なので、このようにしれっと無視されては困ります。解析手順書とAIが作成したコードとの整合性を確認することが重要です。このプロセスは、人間の目で行うか、別のAIにチェックさせることも可能です。
患者背景表
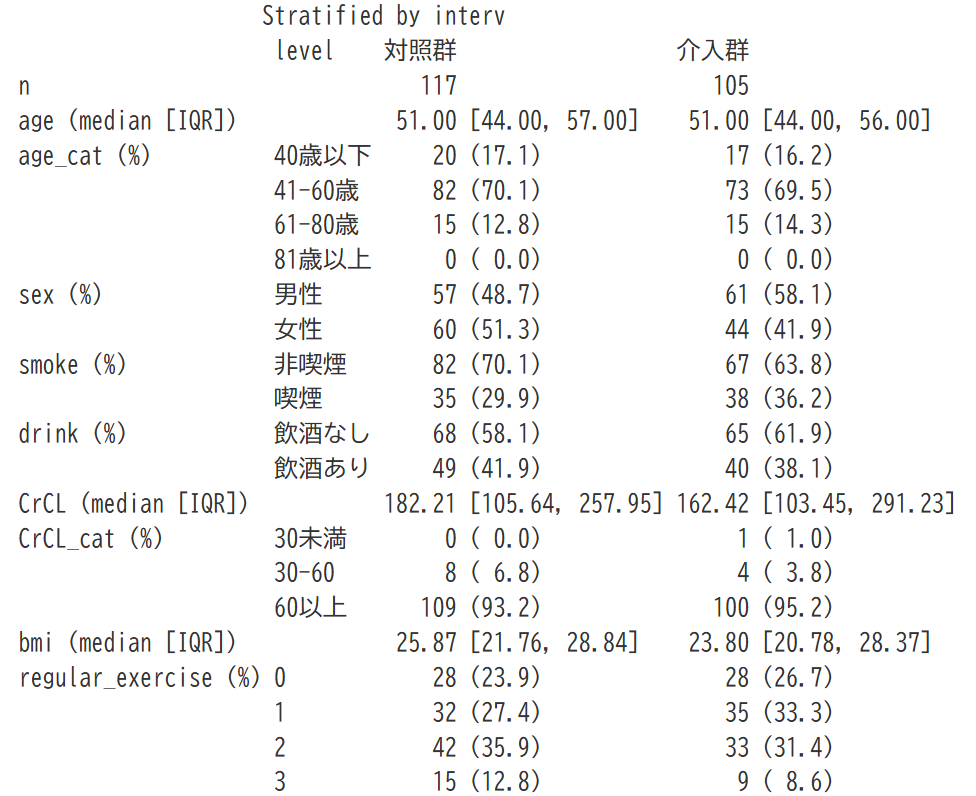
患者背景表は指示通り、介入の有無で群分けを行い、年齢やクレアチニンクリアランスについて連続値とカテゴリ化したものを提示しています。
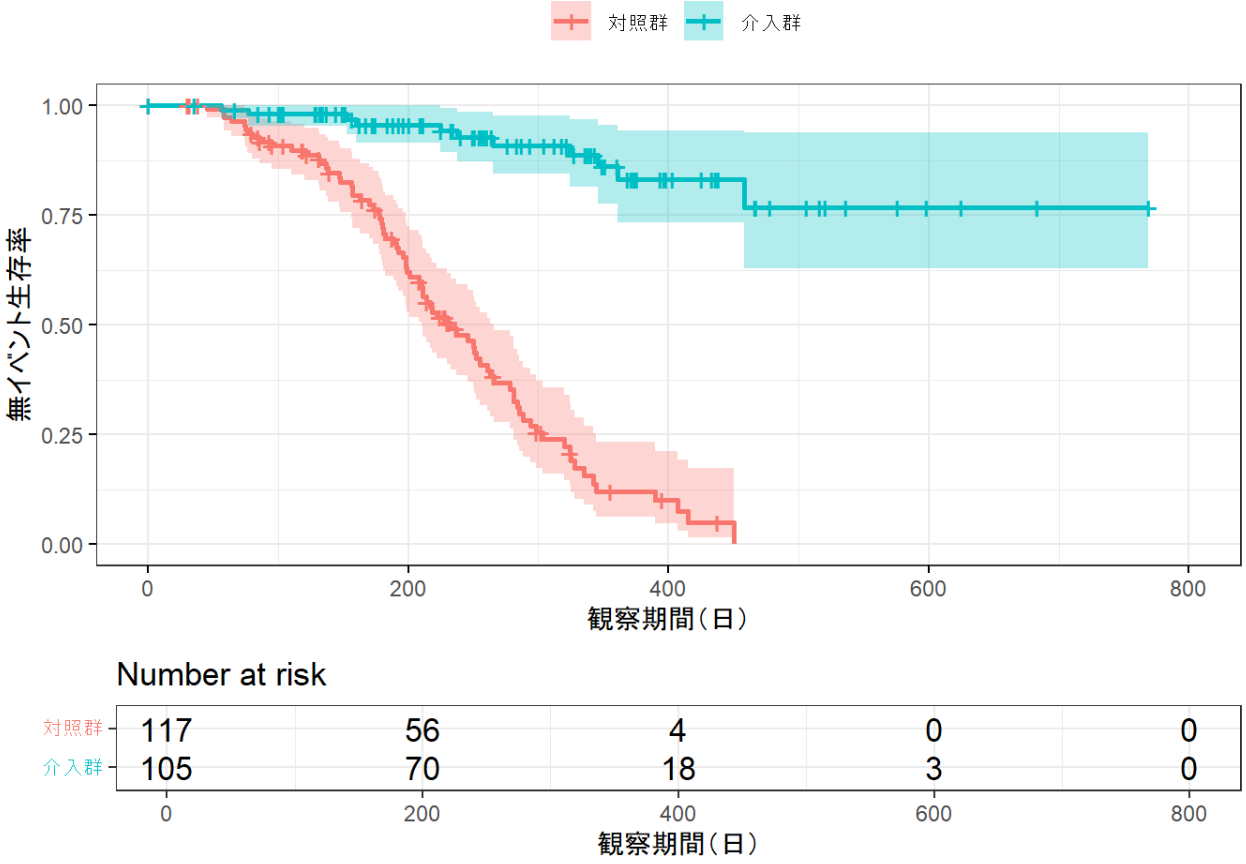
主解析のカプランマイヤー曲線
カプランマイヤー曲線も非常にみやすいです。
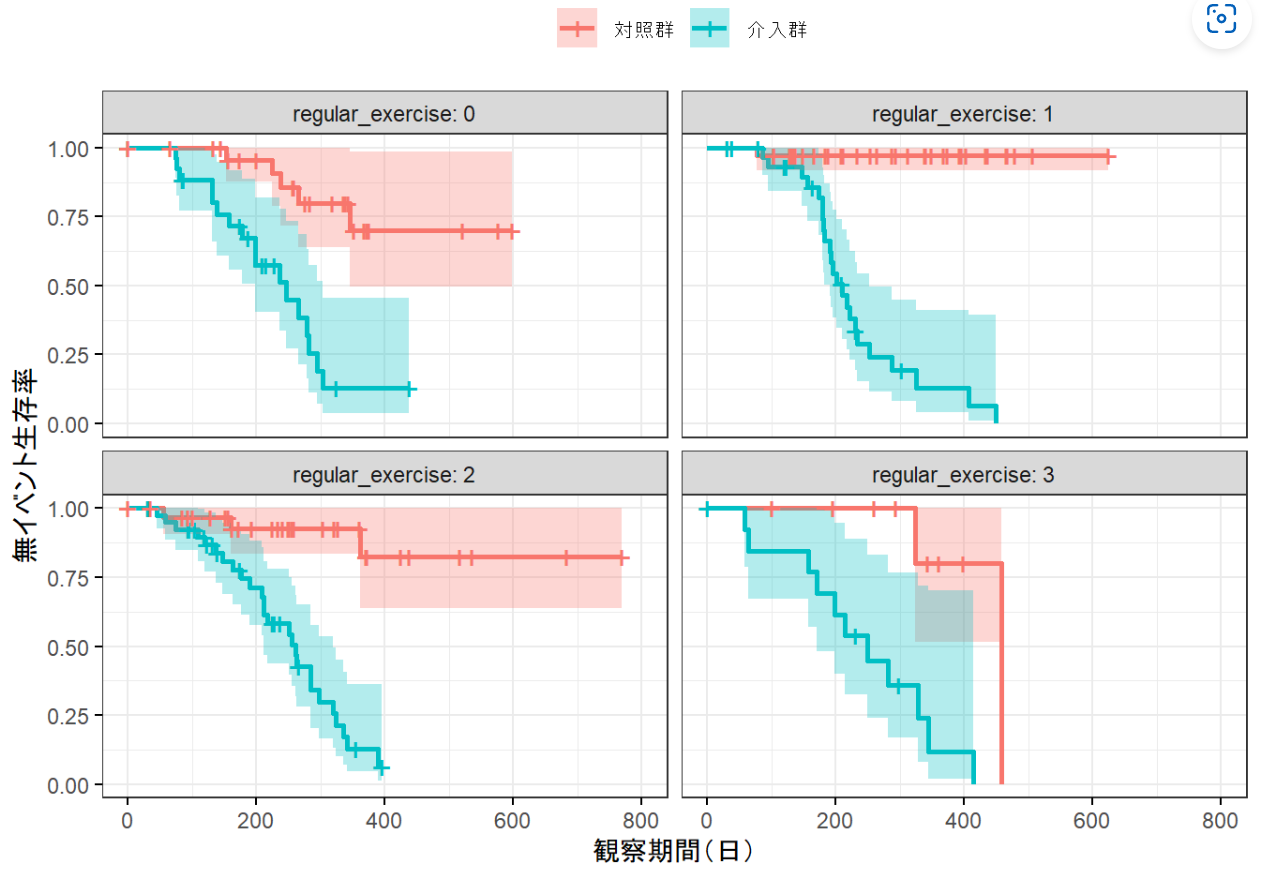
運動習慣ごとのサブグループ解析
運動習慣ごとのサブグループ解析も指示通り実行してくれています。

analysis_planに従って、Quartoで解析レポートを作成してください。データは"datasheet.csv"を使用してください。
各変数のデータ型や値についてはdata_dictionaryを参照してください。