

Contents
今回は、臨床疑問から統計手法を調査する一連の流れを解説します。
臨床疑問~統計手法決定までの流れ
まずは、普段行っている臨床研究コンサルタント業務の流れを細分化してどの部分をAIに任せることができるかを考えてみます。
おおまかには下記のような流れで進んでいきます。
- 研究内容を聴取し研究デザインに必要な情報をピックアップ
- 研究デザインをフレームワークに当てはめる
- 潜在的トラブルシューティング
- 必要なデータ形式や統計手法を提案
1. 研究内容の聴取
まずは、研究者からプレゼンテーション資料や研究計画書を見せてもらいながら研究内容を聴取していきます。このとき、頭の中では研究デザインに必要な情報をピックアップしています。そして、研究デザインに必要なピースを埋めるために足りない情報は適宜掘り下げて質問をする必要があります。
2. 研究デザインを枠組みに当てはめる
ピックアップした情報から、研究デザインの大枠を決めます。
臨床研究では決まったある程度決まった”型”あり、基本的にその型に当てはめるのがよいです。なぜなら、論文の読み手(査読者含む)はその型通り進むことを期待して読み進めていくことが多いからです。
例えば大まかには下記の3つが研究デザインに必要な情報です。
- 研究目的(因果推論、予測、記述、因子探索)
- アウトカムの種類(連続変数、カテゴリ変数、time-to-eventなど)
- クラスターの有無(経時測定データなど)
例えば因果推論、time-to-event、クラスターなしという組み合わせであれば、多くの場合生存時間解析の枠組みに当てはまります。
3. 潜在的トラブルシューティング
欠測値への対処や、上記の生存時間解析の例だと、競合リスクが問題になるか、などを確認します。統計手法で対応することもあれば、適格基準やフォローアップ期間を見直してデザインの修正で対応することもあります。
4. 必要なデータ形式や統計手法を提案
ここまでが決まったあとは解析手法で迷うことは少ないです。例えば2値アウトカムでクラスターが無ければ、ロジスティック回帰分析が最も一般的です(因果推論の場合IPWやparametric g-formulaなどを用いることもあります)。
実際のコンサルの流れはこんな感じです。次は、これらのステップをどのAIに任せるべきか考えます。
どのステップをどのAIモデルに任せるか考える
4つのステップをどのAIに任せるかがポイントです。
- 研究内容の聴取し研究デザインに必要な情報をピックアップ
- 研究デザインをフレームワークに当てはめる
- 潜在的な問題(バイアス)への対処
- 必要なデータ形式や統計手法を提案
Deep Research
まず、ステップ2-4はDeep Researchのようなリサーチ特化型のAIモデルに任せるのが良いでしょう。
Deep ResearchはChatGPT有料版限定の機能で下記のようにプランごとに利用制限があります。
| プラン | 料金 | 利用制限 |
| Plus | 月額20ドル | 月10回まで |
| Pro | 月額200ドル | 月100回まで |
以前の記事で紹介したように、Deep Researchは適切なプロンプトを与えると、臨床疑問をPICO形式で伝えるだけで素晴らしい働きをしてくれます。今回は、PICOだけでなくステップ1で収集したもっと詳細な情報を与えることで、さらにアウトプットの質が向上させていきます。
GPTs(通称コンサルくん)
問題はステップ1「研究内容の聴取し研究デザインに必要な情報をピックアップ」です。
これは、研究者に記述してもらうのが一番早いですが
- 伝えるべき情報がわからない
- 説明するのが面倒くさい
などの問題点があるため、研究者任せにはできません。
そのため、AIを使ってどのように「研究内容の聴取し掘り下げる」かが大事です。
この問題を解決するため、GPTsを自作することにしました(※GPTsとは、ChatGPTのモデルにあらかじめ設定したプロンプトや知識を与えることで動作がカスタマイズされたモデルです。ChatGPTの有料版ユーザーが作成・使用することができます)。
作成したGPTsは【関西風】臨床研究コンサルくん」(以下、コンサルくん)です。
コンサルくんは、我々が行う「1. 研究内容の聴取」のステップを実行する忠実なAIで、下記2つの問題点を克服するために使用します。
- 問題点1: 「伝えるべき情報がわからない」を克服するために、適切な質問や要約を通して研究者が情報を引き出すガイドをしてくれます。
- 問題点2: 「説明するのが面倒くさい」を克服するために、コンサルくんは巧みな話術で楽しく話を広げてくれます。
最初は標準語verで作っていましたが回答するのがわずらわしく感じたので、会話自体が楽しい雰囲気になるようコテコテの関西弁にしました。すると、どうでしょうか。会話しながら思わず笑みがこぼれてしまうようになり、気づけば会話がスイスイと進むようになりました。
下記は利用した方に送っていただいたスクショですが、研究に対する悩みにもめちゃくちゃ寄り添ってくれるイイ奴です(笑)

ただイイ奴なだけでなく、コンサルくんは、気さくな会話の中でも下記について上手いこと聞き出してくれます。
- 研究テーマ・目的(因子探索・因果推論・予測モデル・記述研究)
- 対象患者の選定基準(組入れ基準・除外基準)
- 研究のデータ収集方向(前向き or 後ろ向き)
- 興味のある曝露や介入の種類(薬剤の有無、検査値など)
- アウトカム(目的変数)の具体的な設定(死亡、再発、数値変化など)
- 観察期間・追跡方法・対照群の設定(症例対照、コホートなど)
- 考慮すべき交絡要因や共変量(年齢、性別、基礎疾患など)
- 効果修飾・サブグループ解析の必要性や可能性
- データ構造の特性(縦断データ、多施設データなど)
- サンプルサイズや予測されるイベント発生数
- 欠測値の有無や程度
そして、最後には収集した項目のサマリを箇条書きでまとめてくれます。これにより「2. 研究デザインの落とし込み」に必要な情報が揃います。

AIを使った臨床疑問~統計手法提案の流れ
ここまでをふまえ、AIを使った臨床疑問~統計手法提案の流れは次のようになります。
コンサルくん担当
- 研究内容の聴取し研究デザインに必要な情報をピックアップ
Deep Research担当
- 研究デザインをフレームワークに当てはめる
- 潜在的な問題への対処
- 必要なデータ形式や統計手法を提案
いざ実践!!
コンサルくんの使い方
まずはコンサルくんに研究相談にのってもらいます。なんでもよいので気楽に話しかけてみて下さい。
会話の切り出し
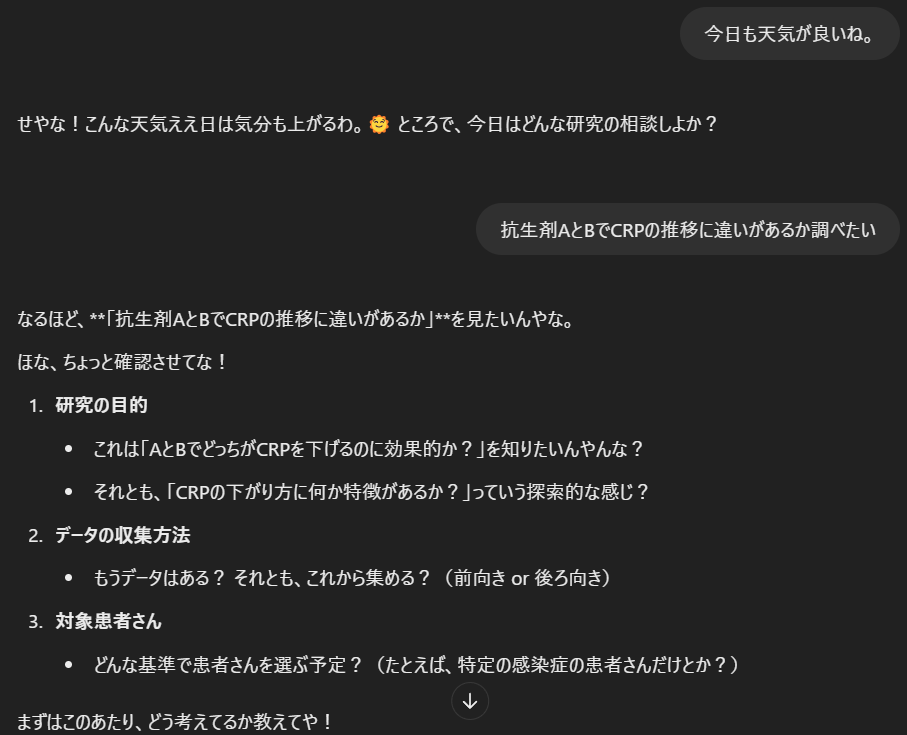
コンサルくんは一度に多くを聞き出さず、途中でうまく要約しながら、研究デザインに必要な情報を引き出してくれます。
サマリーの提示
会話が進み一通り情報が揃ったと判断したら、会話の最後に集めた情報を箇条書きで提示してくれます。
以下はコンサルくんがまとめてくれたサマリーになります。
- 目的: 抗生剤AとBでCRPの下がり方に違いがあるか探索する
- データ: 後ろ向き(既存のデータを使う)
- 対象: 敗血症患者
- CRP測定: 患者ごとにバラバラ(統一されたタイミングなし)
- 抗生剤の投与基準: 医師の判断(ランダム割り付けではない)
- 交絡因子: 重症度(SOFAスコアなど)・年齢
- 観察期間: 退院するまで
- データの構造: 縦断データ(同じ患者のCRPを複数回測定)
- サンプルサイズ: 100名くらい
- 欠測データ: CRPの欠測は約10%
- アウトカム: CRPの推移+ICU滞在日数も分析対象
- 効果修飾: SOFAスコアによる効果の違いも検討
このサマリーが研究デザインに必要なエッセンスになるので、次の手順でDeep Researchに渡すプロンプトにコピペします。
Deep Research
次に、Deep Researchにコンサルくんがまとめてくれたサマリーを使って統計手法をリサーチしてもらいます。
そして、提案する統計手法ごとに下記の情報を調査してもらいます。
- 統計解析手法
- 必要なデータの形式
- Rコードのサンプル
- Rコードのマニュアル
- 同じ手法を実践した論文
- Methodで引用する論文
以下はDeep Research用のプロンプトです。
先程コンサルくんが作成したサマリーを【★★ここにサマリーを貼り付ける★★】の箇所に貼り付けるだけで下記の項目について詳細な情報を取得できます。
# 臨床疑問から統計解析手法を調査
## 1. 調査の目的
臨床疑問をもとに適切な統計解析手法を明らかにする。
## 2. 明らかにすべきこと
- 臨床疑問に対する適切な統計手法
- 解析に必要なCSVファイルの形式
- 解析に用いるRコードのサンプル
## 3. 研究デザイン
【★★ここにサマリーを貼り付ける★★】
## 4. 情報源
- 論文
- ウェブサイト
- 除外するキーワード: 指定なし
- 対象言語: 英語 or 日本語
- 優先順位
- 論文: インパクトが高いもの
- ウェブサイト: Rのサンプルコードが載っているもので信頼度が高いもの
## 5. 出力形式
下記のフォーマットに沿って回答してください。
### [推奨される主解析1]
- 統計手法の詳細
- Rコード
- 統計手法の前提となる仮定や適用する際の注意点
- 必要なCSVファイルの形式
- Rのサンプルコードが載っているウェブサイト(**できるだけ多く提示**)
- この手法を用いた臨床研究論文
- 論文で引用すべき文献
### [推奨される副次解析1] ※推奨される主解析1と同様の回答形式
### [推奨される主解析2] ※推奨される主解析1と同様の回答形式
### [推奨される副次解析2] ※推奨される主解析1と同様の回答形式
**Note:** 最終レポートは日本語で出力してください。
それでは、実際にサマリーとプロンプトを用いてDeep Researchとやりとりしたところをみてみましょう。
プロンプトをsubmitした後、まずはこのような一次応答があります。

ここで詳細に指定することも可能ですが、「良い感じで」などとAIにベストプラクティスを委ねてしまっても問題ありません。
今回の調査開始からアウトプットまでの時間は約10分でした。
DeepResearchによる回答まとめ
主解析の提案
主解析は線形混合効果モデル (LMM)が提案されました。今回のような連続値アウトカムの経時測定データに対しては一般的に用いられます。

LMMについて概要と適用、(画像では切れてますが)モデル設定、分布とリンク関数、共変量の調整といったセクションに分けて、論文を参照しながら詳細に解説してくれています。
データ形式と前処理
LMMを実装するために準備するデータ形式を解説しています。
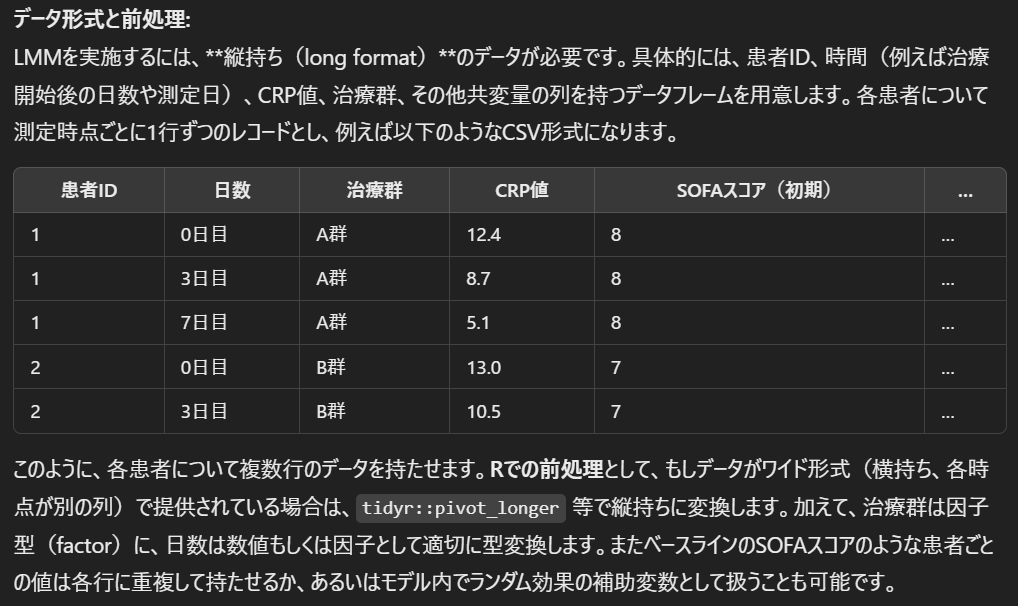
このような具体例があると、実際にデータを準備する際に大変参考になります。
Rでの実装例
LMMをRで実装するためのコード例を解説しています。データの前処理から実際の解析まで詳細なコードが提示されています。
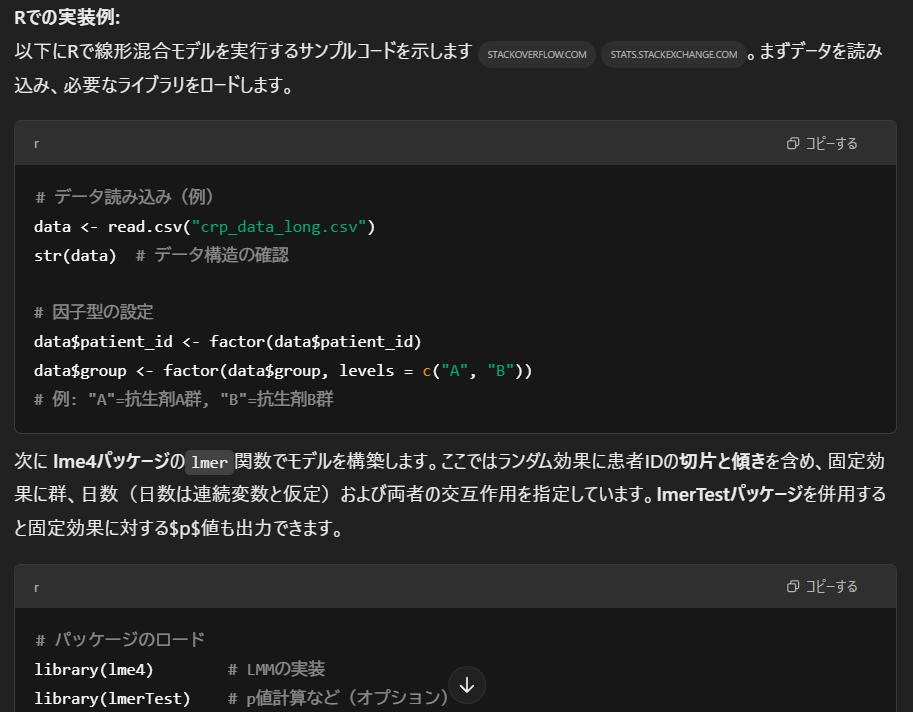
このようにコード例があると、実際に解析を行う際に大変参考になります。
仮定と注意点
LMMを解析に用いる際暗黙下で置いている仮定や注意点について解説しています。

データの欠測メカニズムの仮定(Missing at Random, MAR)や、モデルの残差の正規性の過程など、論文だと査読でStatistical Reviewerに指摘されるような点についても解説してくれています。
参考文献・情報源
LMMを研究に使用するときに参照すべき情報を提示してくれています。
- Methodで引用する論文
- Rのサンプルコードが載っているウェブサイト
- LMMを実践した論文

解析時に役立つのはもちろん、論文執筆時もIntroduction, Methods, Discussionの各セクションで引用する論文を提示してくれています。
まとめ
コンサルくんとDeep Researchを組み合わせることで、臨床研究のデザインから統計解析手法までをカバーするコンサルティングの流れを実行することができました。
出来上がったレポートは素晴らしいの一言で、統計手法の提案だけでなく、実践するために必要な情報が網羅されています。
まとめ:臨床疑問から統計手法を調査する方法
- 1. GPTs「臨床研究コンサルくん」に研究内容を聞き出す
- 2. Deep Researchにより統計解析手法をリサーチする
- 3. 下記の情報が得られる
- 統計解析手法
- 必要なデータの形式
- Rコードのサンプル
- Rコードのマニュアル
- 同じ手法を実践した論文
- Methodで引用する論文
是非みなさん、今回紹介したメソッドを活用して臨床研究の効率化を実践してみてください!
