
この記事を読んでできること
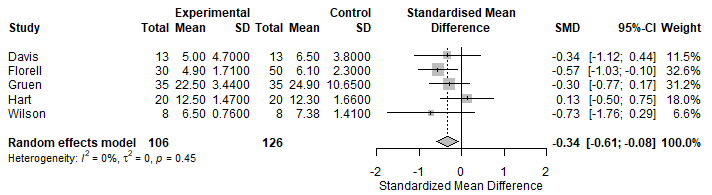
この記事では、CursorというAIエディタを使ってRを動かし、メタアナリシスを行います。具体的な目標地点として、一切コードを書かずにAIに指示を出すのみで下記のようなフォレストプロットを作成します。
AIエディタを使えば、AIに指示するだけで全ての解析が完了し、綺麗なTableやFigureが完成します。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。
AI活用でコードを書かずにメタアナリシスをしよう!
AIエディタ: Cursor (Version 0.44.8)
モデル: gemini-2.0-flash-exp
以下のステップで分析を進めていきます。
- データセットの準備:
Fleiss93contデータセットを読み込み、データの構造を確認します。 - メタアナリシスの実行:
metacont関数を用いて、メタアナリシスを行い、結果を確認します。 - フォレストプロットの作成: メタアナリシスの結果を視覚的に表現するフォレストプロットを作成します。
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。
それでは、早速分析を始めましょう。

1. データセットの準備
metaパッケージのFleiss93contデータセットを使用します。
このデータセットでは心理療法ありと心理療法なしそれぞれの群について、連続値アウトカムの値とその標準偏差が存在します。
(Ctrl+K) ‘meta’パッケージの’Fleiss93cont’データを読み込んで、’df’という名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(meta)
data("Fleiss93cont")
df <- Fleiss93cont
データセットをRに読み込んだら、まず最初に行うべきことはデータの中身を確認することです。データの形式や最初の数行のデータを確認することで、データ全体の概要を把握します。
(Ctrl+K) dfのデータ形式を確認する。
str(df)
'data.frame': 5 obs. of 8 variables:
$ study : chr "Davis" "Florell" "Gruen" "Hart" ...
$ year : int 1973 1971 1975 1975 1977
$ n.e : int 13 30 35 20 8
$ mean.e: num 5 4.9 22.5 12.5 6.5
$ sd.e : num 4.7 1.71 3.44 1.47 0.76
$ n.c : int 13 50 35 20 8
$ mean.c: num 6.5 6.1 24.9 12.3 7.38
$ sd.c : num 3.8 2.3 10.65 1.66 1.41
| 変数名 | 説明 |
study |
研究の識別子またはラベル |
year |
研究が発表された年 |
n.psyc |
心理療法グループにおける観察数(サンプルサイズ) |
mean.psyc |
心理療法グループにおける推定平均値 |
sd.psyc |
心理療法グループにおける標準偏差 |
n.cont |
対照(コントロール)グループにおける観察数(サンプルサイズ) |
mean.cont |
対照グループにおける推定平均値 |
sd.cont |
対照グループにおける標準偏差 |
2. メタアナリシスを実行しよう
今回扱うアウトカムは連続変数のため、メタアナリシスのマニュアルサイトでも使用されているmetacont関数を使用します。
metacont関数のひな型は下記になります。
# meta パッケージをインストール
# install.packages("meta")
library(meta)
# データの読み込み (data.csv が同じディレクトリにあると仮定)
data <- read.csv("data.csv")
# メタアナリシスを実行
meta_analysis <- metacont(
n.e = n.e, # 実験群のサンプルサイズを指定 (data.csv の n.e 列に対応)
mean.e = mean.e, # 実験群の平均値を指定 (data.csv の mean.e 列に対応)
sd.e = sd.e, # 実験群の標準偏差を指定 (data.csv の sd.e 列に対応)
n.c = n.c, # 対照群のサンプルサイズを指定 (data.csv の n.c 列に対応)
mean.c = mean.c, # 対照群の平均値を指定 (data.csv の mean.c 列に対応)
sd.c = sd.c, # 対照群の標準偏差を指定 (data.csv の sd.c 列に対応)
data = data, # データフレームを指定 (data.csv を読み込んだデータフレーム)
studlab = study, # 各研究のラベルを指定 (data.csv の study 列に対応)
sm = "SMD", # 効果量の種類を指定 (ここでは標準化平均差 "SMD" を指定)
fixed = FALSE, # 固定効果モデルを使用するかどうか (FALSE でランダム効果モデル)
random = TRUE # ランダム効果モデルを使用するかどうか (TRUE でランダム効果モデル)
)
# 結果の表示
print(meta_analysis)
forest(meta_analysis) # フォレストプロットの表示
metacont関数では、統合する効果量の指標として("MD"、"SMD"、"ROM")のいずれかを選択します。
| 指標 | 使用条件 |
| "MD" (Mean Difference) - 平均差 | 介入群と対照群の間の「絶対的な平均値の差」を評価する尺度 |
| "SMD" (Standardized Mean Difference) - 標準化平均差 | 介入群と対照群の平均値の差を、標準偏差で標準化した尺度 |
| "ROM" (Ratio of Means) - 平均比 | 介入群の平均値と対照群の平均値の比を評価する尺度。 |
解析の目的やデータの特性に応じて、適切な尺度を選択してください。
メタアナリシスでは、主に固定効果モデルとランダム効果モデルの2つが用いられます。
| モデル | 仮定 | 特徴 | 注意点 |
| 固定効果 | 全ての研究は共通の「真の効果量」をもつ。ばらつきはサンプリング誤差とみなす。 | 信頼区間が狭くなり、p値も小さくなりやすい。 | 研究デザインや対象者が異なる場合に誤った結論につながるリスクあり。 |
| ランダム効果 | 研究ごとに効果量が異なる。ばらつきはサンプリング誤差と研究間の効果量の違いによる。 | 信頼区間が広くなる傾向がある。 | 研究数が少ない場合や極端な異質性がある場合は、推定が不安定になる可能性あり。 |
モデルの使い分け
固定/ランダム効果モデルのどちらの結果を採用するかは研究によって様々です。
- ランダム効果モデルを採用する。
- 異質性の大きさで固定/ランダム効果モデルを選択する(例:後述するI²(アイスクエア)統計量が50%以下である場合に固定効果モデルを採用する)。
異質性の評価指標
Q検定 (Cochran's Q test)とI²(アイスクエア)統計量 が一般的に用いられます。
| 指標 | 目的 | 解釈と注意点 |
| Q検定 | 研究間の効果量に統計的に有意なばらつきがあるかを検定。 | 研究数が少ないと検出力が低く、異質性があっても見逃すことがある。研究数が多いと些細な異質性でも有意になりやすい。 |
| I²統計量 | 研究間異質性の「大きさ」を比率(%)として示す。Q検定の結果だけでなく、実質的なばらつきの度合いを把握したい際に用いられる。 | 0-25%: 異質性は低い。25-50%: 中程度。50-75%: 高い。75-100%: 非常に高い。研究数やデザインによって解釈が変わる。 |
それではメタアナリシスを実行していきます。
各群のサンプルサイズ、アウトカムの平均値、およびその標準偏差を指定します。
必要なデータはパッケージや関数によって異なるので、パッケージのドキュメントを見たりAIに質問したりしてあらかじめ確認が必要です。
(Ctrl+K) metaパッケージのmetacont関数を使ってメタアナリシスを行います。
介入群のサンプルサイズはn.e、平均値はmean.e、標準偏差はsd.eです。
対照群のサンプルサイズはn.c、平均値はmean.c、標準偏差はsd.cです。
データフレームはdfです。
meta_analysis <- metacont(
n.e = n.e,
mean.e = mean.e,
sd.e = sd.e,
n.c = n.c,
mean.c = mean.c,
sd.c = sd.c,
data = df,
studlab = study,
sm = "SMD",
fixed = FALSE,
random = TRUE
)
print(meta_analysis)
forest(meta_analysis)
Number of studies: k = 5
Number of observations: o = 232 (o.e = 106, o.c = 126)
SMD 95%-CI z p-value
Random effects model -0.3434 [-0.6068; -0.0801] -2.56 0.0106
Quantifying heterogeneity:
tau^2 = 0 [0.0000; 0.7255]; tau = 0 [0.0000; 0.8518]
I^2 = 0.0% [0.0%; 79.2%]; H = 1.00 [1.00; 2.19]
Test of heterogeneity:
Q d.f. p-value
3.68 4 0.4514
Details on meta-analytical method:
- Inverse variance method
- Restricted maximum-likelihood estimator for tau^2
- Q-Profile method for confidence interval of tau^2 and tau
- Hedges' g (bias corrected standardised mean difference; using exact formulae)
全体的な概要
- 研究数 (k): 5つの研究が統合されています。
- 観測数 (o): 合計232の観測データがあり、内訳は実験群(o.e)が106、対照群(o.c)が126です。
- モデル: ランダム効果モデルが使用されています。
- 効果量: 標準化平均差 (SMD) であるHedges' gが用いられています。
効果量
- SMD (Hedges' g): -0.3434
- これは、統合された効果量の推定値が-0.3434であることを示しています。
- SMDは標準偏差単位での効果量の差を表しており、負の値は実験群が対照群と比較して効果が小さい(または負の効果)であることを示唆します。
- 95%信頼区間 (95%-CI): [-0.6068; -0.0801]
- 真の効果量が、95%の確率でこの範囲内に存在すると考えられます。
- 信頼区間の上限と下限が両方とも負であることから、統計的に有意な負の効果である可能性が高いです。
- z値: -2.56
- 効果量の統計的な有意性を評価するための指標です。
- p値: 0.0106
- p値が0.05よりも小さい(p < 0.05)ため、帰無仮説(効果量が0)は棄却され、統計的に有意な効果があると言えます。
- この場合、実験群は対照群と比較して、統計的に有意に低い値を示しています。
異質性
- τ² (tau^2): 0 [0.0000; 0.7255]
- 研究間分散(効果量のばらつき)の推定値です。
- 推定値が0であり、信頼区間の下限も0であることから、研究間の異質性はほぼないと考えられます。信頼区間の上限が0.7255とやや大きいため、異質性がないとは断定できない場合もありますが、推定値は0です。
- τ (tau): 0 [0.0000; 0.8518]
- τ²の平方根であり、研究間の効果量の標準偏差の推定値です。
- 推定値が0で、信頼区間の下限も0であるため、研究間のばらつきはほぼないと言えます。信頼区間の上限が0.8518とやや大きいため、異質性がないとは断定できない場合もありますが、推定値は0です。
- I² (I-squared): 0.0% [0.0%; 79.2%]
- 研究間異質性の割合を示す指標です。
- 推定値が0%であることから、研究間異質性はほとんどないと言えます。信頼区間の上限が79.2%とやや大きいため、異質性がないとは断定できない場合もありますが、推定値は0%です。
- H: 1.00 [1.00; 2.19]
- 研究間のばらつきの程度を示す指標で、I^2と関連しています。
- Hの値が1に近いほど、異質性が低いことを示します。
- Q値: 3.68
- 研究間の異質性を検定するための統計量です。
- 自由度 (d.f.): 4
- 研究数(k) - 1 = 5 - 1 = 4
- Q検定のp値: 0.4514
- p値が0.05よりも大きいため、研究間の異質性は統計的に有意ではないと判断されます。つまり、研究間の効果量に統計的に有意なばらつきは見られません。
結果の解釈
- ランダム効果モデルを用いたメタアナリシスの結果、統合された効果量は統計的に有意な負の値(-0.3434)であり、実験群は対照群と比較してアウトカムのをより大きく下げることがわかります
- 研究間の異質性は小さいと考えられるますが、I^2やtau^2の信頼区間が広いことには注意が必要です。これは、研究数が少ない場合によく見られます。
3. フォレストプロットの作成
続いて、フォレストプロットを作成します。metacont関数の結果を格納したmeta_analysisオブジェクトにforest関数を適用することで簡単に作成できます。
(Ctrl+K) フォレストプロットを作成して。
forest(meta_analysis,
xlim = c(-2, 2),
xlab = "Standardized Mean Difference",
main = "Forest Plot of Meta-Analysis")
(Ctrl+K) フォレストプロットを画像として出力する。全体が入るようにサイズを調整して。
png("forest_plot.png", width = 800, height = 600)
forest(meta_analysis,
xlim = c(-2, 2),
xlab = "Standardized Mean Difference",
main = "Forest Plot of Meta-Analysis")
dev.off()
作業フォルダに保存された画像ファイルを開きます。
フォレストプロットを作成することができました。
今回はアウトカムが連続値である研究を題材としましたが、2値アウトカム(リスク差やオッズ比)、生存時間型アウトカム(ハザード比)などに対しても、同様の手順で進めることができます。