


Contents
この記事を読んでできること
この記事では、CursorというAIエディタを用いてRを動かし、生存時間解析を行う方法をご紹介します。具体的には、一切コードを書かずにAIに指示するだけで下記のようなFigureやTableを作成します。
AIエディタを使えば、AIと会話するだけで全ての解析が完了し、綺麗なTableやFigureが完成します。
AIエディタについてもう少し詳しく知りたい方はこちらをご覧ください。
本記事と同じ解析環境を準備する手順は下記の記事で詳細に解説しています。
AI活用でコードを書かずに生存時間解析をしよう!
本記事の解析環境
- AIエディタ: Cursor (Version 0.44.8)
- モデル: gemini-2.0-flash-exp
以下のステップで分析を進めていきます。
- データセットの準備:
survivalパッケージのlungデータセットを読み込み、データの内容を確認します。 - データの前処理:
status変数を生存時間解析に適した形式に変換します。 - カプランマイヤー曲線: 全体の生存時間の中央値、1年生存率、2年生存率を算出し、カプランマイヤー曲線を描画します。
- 群分けしたカプランマイヤー曲線: ECOG Performance Score(
ph.ecog)別に群分けし、カプランマイヤー曲線を描画します。 - ログランク検定:
ph.ecogによる生存時間の差をログランク検定で評価します。 - Cox比例ハザードモデル:
ph.ecog,age,sexを説明変数としたCox比例ハザードモデルを作成し、ハザード比を算出します。
解析時にエラーが出て困ったときに読む記事もあるのでご安心ください。
それでは、早速分析を始めましょう。

1. データセットの準備
今回は、Rに標準で付属しているsurvivalパッケージに含まれるlungデータセットを用いて、生存時間解析を行います。
(Ctrl+K) survivalパッケージの’lung’データを読み込んで、’df’という名前で保存する。
※必要に応じてパッケージをインストールしてください。
library(survival)
data(lung)
df <- lung
| 変数名 | 説明 |
| `inst` | 施設コード |
| `time` | 生存時間(日数) |
| `status` | 打ち切り状態 (1=打ち切り, 2=死亡) |
| `age` | 年齢(歳) |
| `sex` | 性別 (男性=1, 女性=2) |
| `ph.ecog` | ECOG PS(Performance Status、全身状態を0-4であらわす) |
| `ph.karno` | 医師が評価したカルノフスキーパフォーマンススコア (0-100) |
| `pat.karno` | 患者が評価したカルノフスキーパフォーマンススコア (0-100) |
| `meal.cal` | 食事での摂取カロリー |
| `wt.loss` | 過去6ヶ月間の体重減少(ポンド) |
データセットを読み込んだら、まず最初に行うべきことはデータの中身を確認することです。データの形式や最初の数行のデータを確認することで、データ全体の概要を把握します。
(Ctrl+K) `df`のデータ形式を確認する。
str(df)
'data.frame': 228 obs. of 10 variables:
$ inst : num 3 3 3 5 1 12 7 11 1 7 ...
$ time : num 306 455 1010 210 883 ...
$ status : num 2 2 1 2 2 1 2 2 2 2 ...
$ age : num 74 68 56 57 60 74 68 71 53 61 ...
$ sex : num 1 1 1 1 1 1 2 2 1 1 ...
$ ph.ecog : num 1 0 0 1 0 1 2 2 1 2 ...
$ ph.karno : num 90 90 90 90 100 50 70 60 70 70 ...
$ pat.karno: num 100 90 90 60 90 80 60 80 80 70 ...
$ meal.cal : num 1175 1225 NA 1150 NA ...
$ wt.loss : num NA 15 15 11 0 0 10 1 16 34 ...
生存時間解析のデータ処理の注意点その1
生存時間解析では、観察期間を示す列と、観察期間終了時点における患者の状態を示す列が必要です。
今回のデータでは、観察期間を示すのがtime列、観察終了時点における患者の状態を示すのがstatus列です。
通常、0がイベントなし(打ち切り)、1がイベントあり(今回は死亡)として解析します。
しかし、今回のデータでは1がイベントなし(打ち切り)、2がイベントあり(死亡)としてコーディングされているため、修正する必要があります。
(Ctrl+K) `df`の`status`列を下記のように修正して`Adata`とする
1→0
2→1
library(dplyr)
Adata <- df %>%
mutate(status = case_when(
status == 1 ~ 0,
status == 2 ~ 1,
TRUE ~ status
))
生存時間解析のデータ処理の注意点その2
生存時間解析では、群分けする変数がカテゴリ変数でないと、カプランマイヤー曲線を作成する際にエラーの原因となります。
今のデータでは、群分け変数であるph.ecogのデータ型がnumつまり実数型になっているため、カテゴリ変数に直す必要があります。
また、2値よりも多いカテゴリをもつ変数、つまりph.ecog(0, 1, 2, 3, 4)のように複数のカテゴリを持つ変数を連続値として扱うときにはモデル(今回はCox回帰モデルを使う)の結果の解釈にも注意が必要です。
どういうことかというと、連続値として扱った場合、0⇒1⇒2⇒3⇒4に変化した時の予後への影響は等間隔だとして扱われてしまいます。具体的には、例えば0⇒1と3⇒4で、同じように予後に影響すると解釈されます。
しかし一般的に0⇒1よりも3⇒4の方が予後が大きく悪くなると考えられるため、実数型データとして扱うのは不適切だと考えられます。
そこで、ph.ecogをカテゴリ変数として適切に扱うために、factor型にデータ変換します。
(Ctrl+K) `Adata`の`ph.ecog`をfactor型に変換
Adata <- Adata %>%
mutate(ph.ecog = factor(ph.ecog))
これでカテゴリ変数として扱うことができるようになりました。
ここまで準備できたところでカプランマイヤー曲線を作成してみましょう。
カプランマイヤー曲線の作成
まずは、コホート全体でのカプランマイヤー曲線を描いてみましょう。
追跡期間はtime列、死亡の有無はstatus列を使用します。
今回はカプランマイヤー曲線を美しく描くためにggsurvplotを使用します。
Rには他にもggsurvfitなどもあるので色々試してみて好みのものを使ってみてください。
(Ctrl+K) `ggsurvplot`関数を用いてカプランマイヤー曲線を作成する。 追跡期間は`time`列、死亡の有無は`status`列、データセットは`Adata`を使用。
library(survival)
library(survminer)
surv_obj <- Surv(time = Adata$time, event = Adata$status)
fit <- survfit(surv_obj ~ 1)
ggsurvplot(fit,
data = Adata,
xlab = "Time (days)",
ylab = "Survival Probability",
title = "Kaplan-Meier Survival Curve")
カプランマイヤー曲線が作成されました。 作業フォルダに画像として保存します。
(Ctrl+K) カプランマイヤー曲線を画像として保存
ggsave("kaplan_meier_curve.png", plot = last_plot())
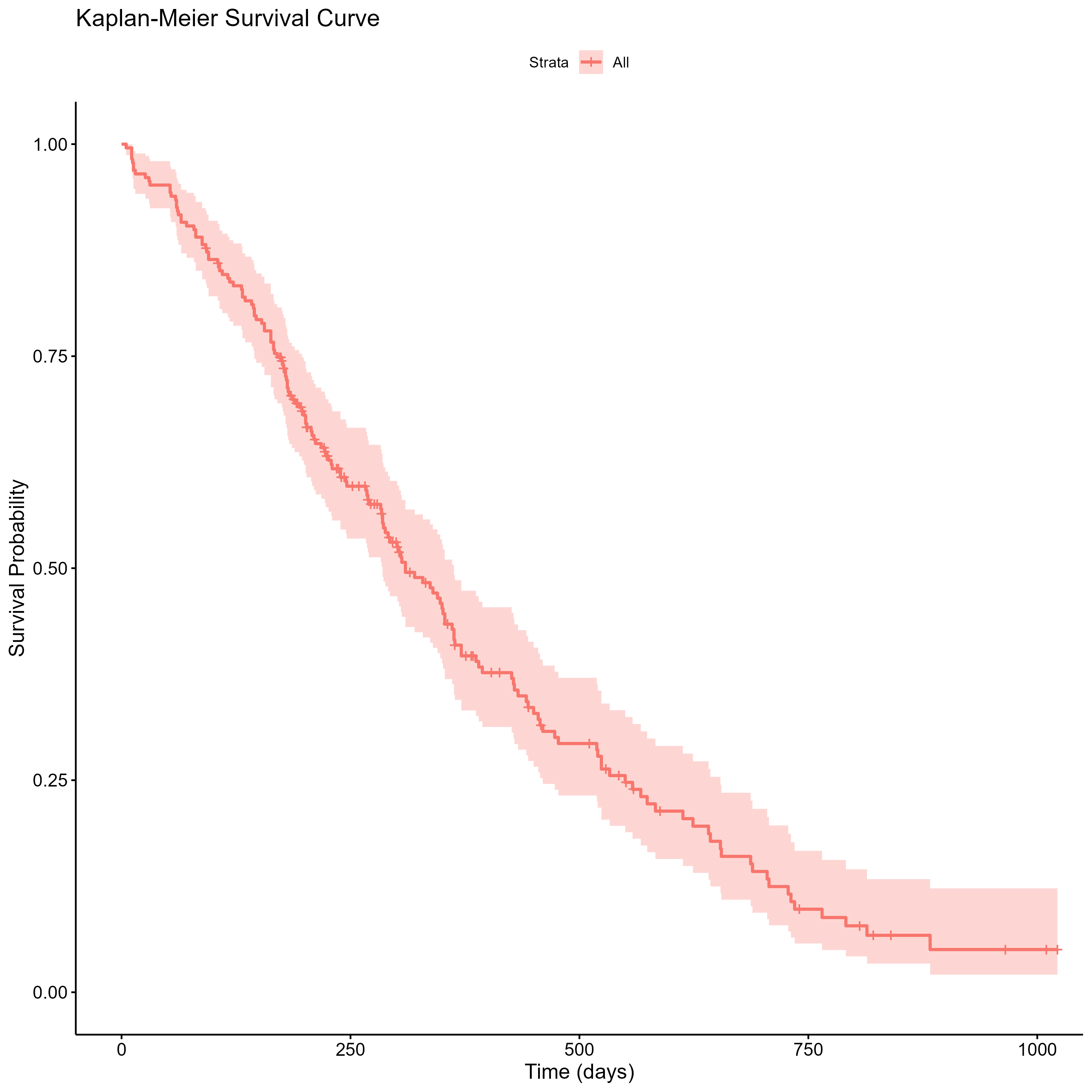
生存期間中央値、年次生存率の推定
生存時間解析の要約指標としては、生存期間中央値や年次生存率を示すのが一般的です。
生存期間中央値はカプランマイヤー曲線を描く時に作成したfitオブジェクトから確認できます。
fitを選択してCtrl+Enterを入力することで結果を表示させることができます。
Call: survfit(formula = surv_obj ~ 1)
n events median 0.95LCL 0.95UCL
[1,] 228 165 310 285 363
medianの値が生存期間中央値を示します。
310日(95%信頼区間 285日~363日)であることが確認できました。
次に、年次生存率を出力します。カプランマイヤー曲線をみると3年目までのほとんどが死亡しているため、1年と2年の生存率を出すことにします。
(Ctrl+K) 1年、2年生存率を確認
summary(fit, times = c(365, 365*2))
time n.risk n.event survival std.err lower 95% CI upper 95% CI
365 65 121 0.409 0.0358 0.3447 0.486
730 13 38 0.116 0.0283 0.0716 0.187
survivalの値がtimeに対する生存率を示します。
1年生存率は0.409 (95%信頼区間: 0.3447-0.486)
2年生存率は0.116 (95%信頼区間: 0.0716-0.187)
であることが確認できました。
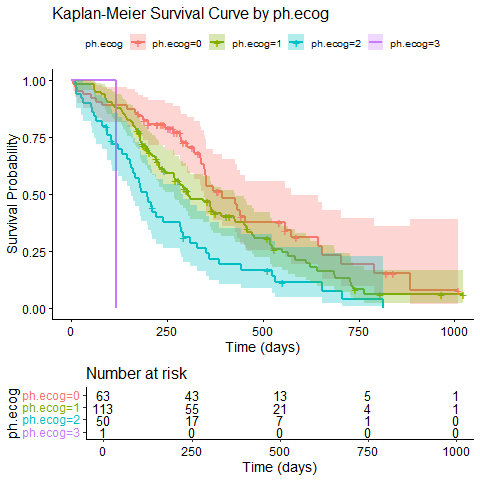
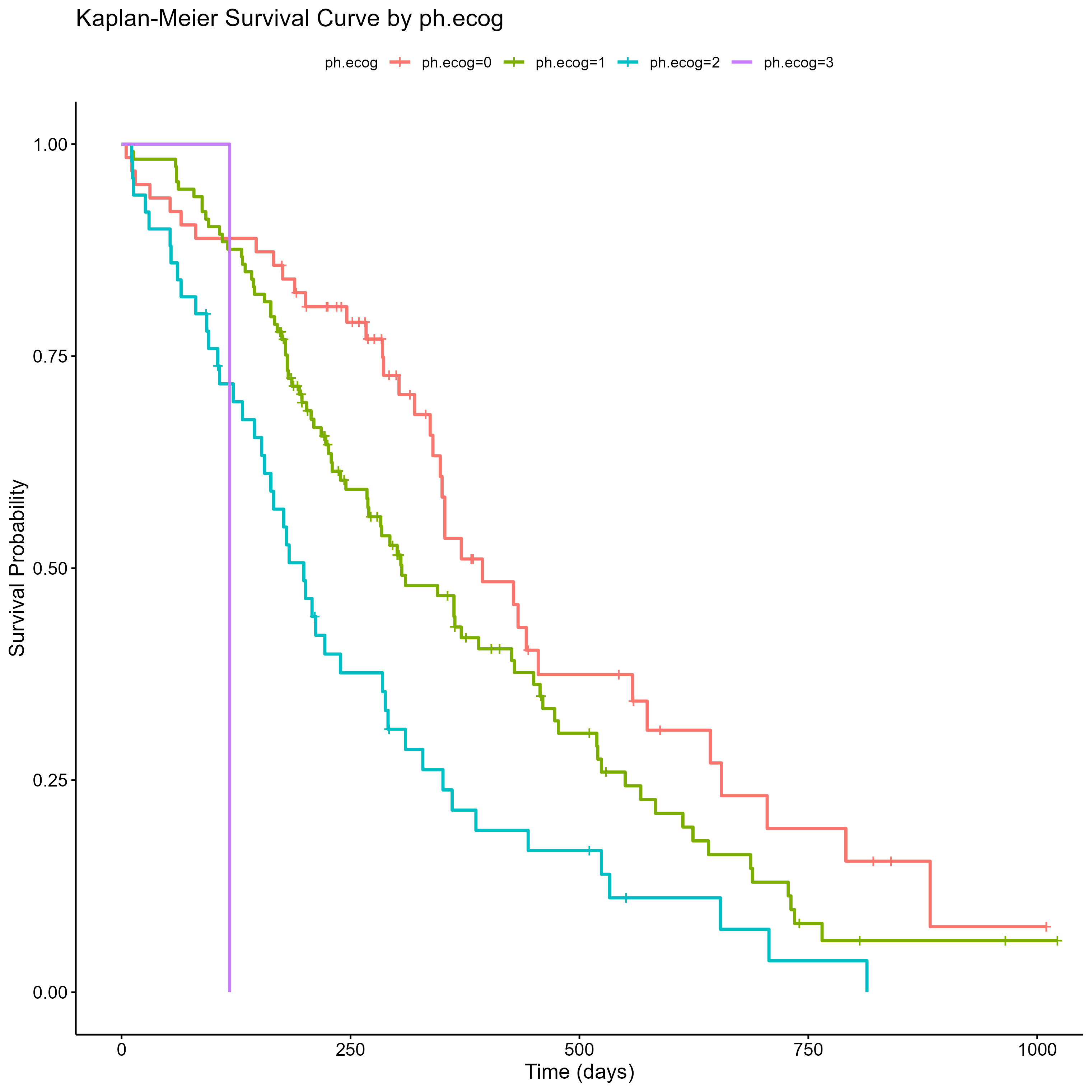
群分けしたカプランマイヤー曲線の作成
次に、今回の分析の目的であったph.ecogごとの予後の比較を行うために、群分けしてカプランマイヤー曲線を作成します。
(Ctrl+K) `ph.ecog`で群分けし、同様にグラフを作成
fit_group <- survfit(surv_obj ~ ph.ecog, data = Adata)
ggsurvplot(fit_group,
data = Adata,
xlab = "Time (days)",
ylab = "Survival Probability",
title = "Kaplan-Meier Survival Curve by ph.ecog",
legend.title = "ph.ecog")
ggsave("kaplan_meier_curve_by_ph_ecog.png", plot = last_plot())
続けて信頼区間を追加します。
(Ctrl+K) カプランマイヤー曲線に信頼区間を追加。
ggsurvplot(fit_group,
data = Adata,
xlab = "Time (days)",
ylab = "Survival Probability",
title = "Kaplan-Meier Survival Curve by ph.ecog",
legend.title = "ph.ecog",
conf.int = TRUE)
ggsave("kaplan_meier_curve_by_ph_ecog_with_ci.png", plot = last_plot())
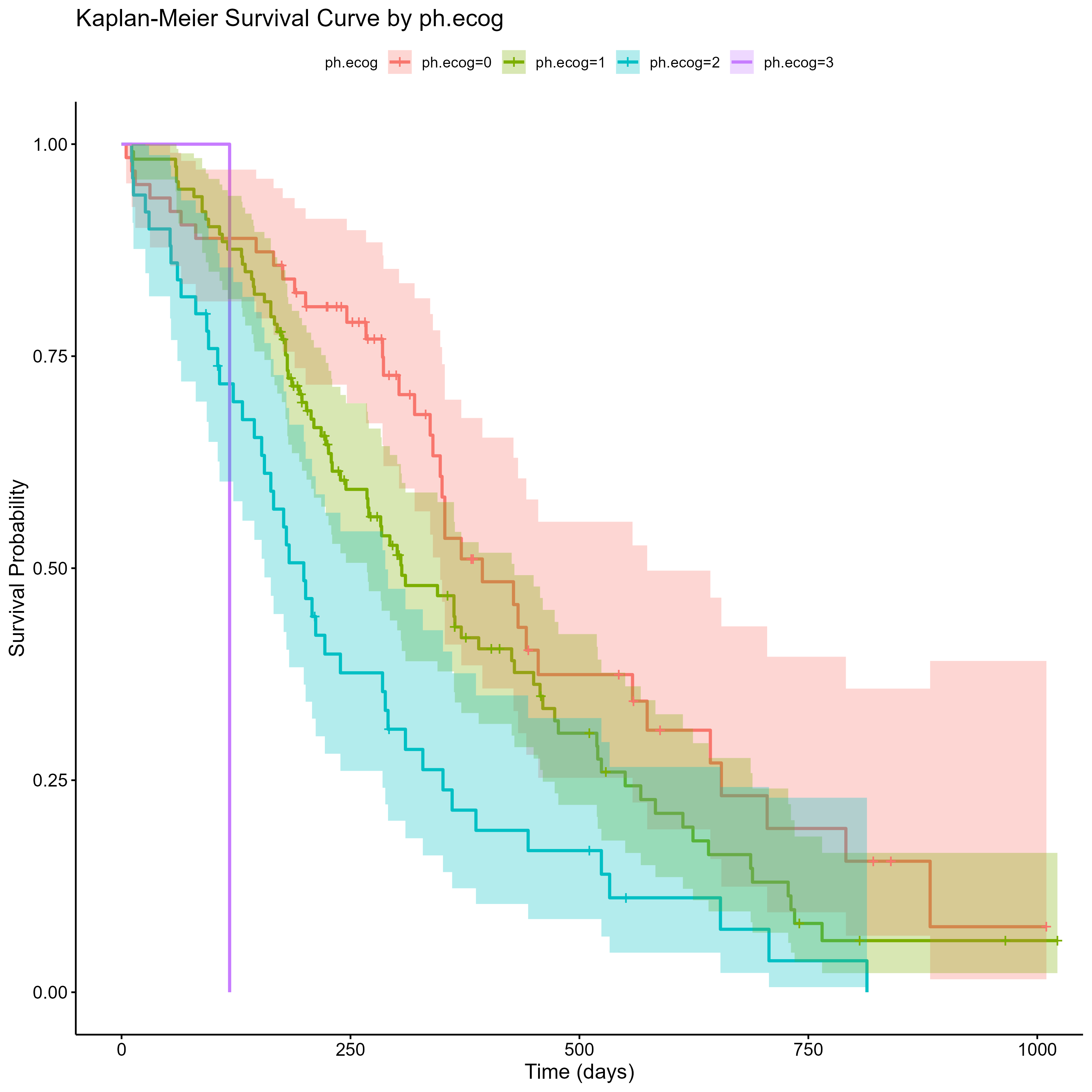
信頼区間が追加されました。 PSが3のグループには信頼区間が表示されていません。これは人数が少ないためと思われます。 それぞれの群に属する人数を把握するためにat riskテーブルを追加します。
(Ctrl+K) at riskテーブルを追加。
ggsurvplot(fit_group,
data = Adata,
xlab = "Time (days)",
ylab = "Survival Probability",
title = "Kaplan-Meier Survival Curve by ph.ecog",
legend.title = "ph.ecog",
conf.int = TRUE,
risk.table = TRUE)
ggsave("kaplan_meier_curve_by_ph_ecog_with_ci_and_risk_table.png", plot = last_plot())
ここで、at riskテーブルが追加されたグラフを出力するときの注意点があります。
ggsurvplotでat riskテーブルを追加した際、`ggsave()`などで保存するとエラーが出ることがあります。 その際は、`png()`関数など他の方法を用いてください。
(Ctrl+K) `png()`関数で画像として保存して
png("kaplan_meier_curve_by_ph_ecog_with_ci_and_risk_table.png")
ggsurvplot(fit_group,
data = Adata,
xlab = "Time (days)",
ylab = "Survival Probability",
title = "Kaplan-Meier Survival Curve by ph.ecog",
legend.title = "ph.ecog",
conf.int = TRUE,
risk.table = TRUE)
dev.off()
論文で使用できる美しいカプランマイヤー曲線を描くことができました。
ログランク検定
(Ctrl+K) `fit_group`を用いてログランク検定を実行
survdiff_result <- survdiff(surv_obj ~ ph.ecog, data = Adata)
print(survdiff_result)
Call:
survdiff(formula = surv_obj ~ ph.ecog, data = Adata)
n=227, 1 observation deleted due to missingness.
N Observed Expected (O-E)^2/E (O-E)^2/V
ph.ecog=0 63 37 54.153 5.4331 8.2119
ph.ecog=1 113 82 83.528 0.0279 0.0573
ph.ecog=2 50 44 26.147 12.1893 14.6491
ph.ecog=3 1 1 0.172 3.9733 4.0040
Chisq= 22 on 3 degrees of freedom, p= 7e-05
p値をみると7e-5、つまり7×10^-5と非常に小さいことがわかります。 ログランク検定の帰無仮説は「群間で生存関数が同じである」なので、その帰無仮説のp値が非常に小さいということは、`ph.ecog`によって予後が異なると解釈できます。 ただし、ログランク検定では交絡因子の調整ができていないことに注意してください。 `ph.ecog`で比較する場合、ランダム化比較試験とは異なるため、かならず何かしらの交絡が生じているはずです。 そこで、交絡因子をモデルで調整するためにCox比例ハザード回帰分析を行います。
Cox比例ハザード回帰分析
Cox回帰モデルでph.ecogの予後への影響を年齢と性別で調整するために、ph.ecogとageとsexを説明変数側に加えます。
(Ctrl+K) Cox回帰を行う。説明変数は`ph.ecog`と`age`と`sex`とする
cox_model <- coxph(surv_obj ~ ph.ecog + age + sex, data = Adata)
summary(cox_model)
Call:
coxph(formula = surv_obj ~ ph.ecog + age + sex, data = Adata)
n= 227, number of events= 164
(1 observation deleted due to missingness)
coef exp(coef) se(coef) z Pr(>|z|)
ph.ecog1 0.410048 1.506890 0.199604 2.054 0.03995 *
ph.ecog2 0.903303 2.467741 0.228078 3.960 7.48e-05 ***
ph.ecog3 1.954543 7.060694 1.029701 1.898 0.05767 .
age 0.010795 1.010853 0.009312 1.159 0.24637
sex -0.545831 0.579360 0.168228 -3.245 0.00118 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
ph.ecog1 1.5069 0.6636 1.0190 2.2284
ph.ecog2 2.4677 0.4052 1.5782 3.8587
ph.ecog3 7.0607 0.1416 0.9383 53.1289
age 1.0109 0.9893 0.9926 1.0295
sex 0.5794 1.7260 0.4166 0.8056
Concordance= 0.637 (se = 0.025 )
Likelihood ratio test= 30.87 on 5 df, p=1e-05
Wald test = 31.43 on 5 df, p=8e-06
Score (logrank) test = 33.56 on 5 df, p=3e-06
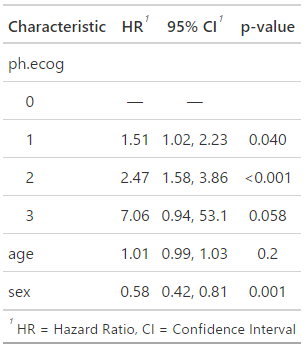
このままでは情報が多すぎて見にくいので、論文に載せる情報としては不要なものを削った解析結果のサマリーを作成します。
回帰モデルの結果の要約にはtbl_regression()関数が便利なので、これを使用します。
(Ctrl+K) `tbl_regression`関数を使用して、解析結果のサマリーを作成してください。
library(gtsummary)
tbl_regression(cox_model, exponentiate = TRUE)
tbl_regression(cox_model, exponentiate = TRUE)の実行結果
論文に提示するためのTableが完成しました。
ハザード比の解釈は複雑なので、厳密ではありませんが、理解しやすさのためリスクの比として解釈を試みます。
パフォーマンスステータス(ph.ecog):
「1」: HR = 1.51。基準(ph.ecog = 0)と比較して、イベントのリスクが約1.5倍高い。
「2」: HR = 2.47。基準と比較して、イベントのリスクが約2.5倍高い。
「3」: HR = 7.06。基準と比較して、イベントのリスクが高い。
年齢(age):
HR = 1.01。年齢が1歳上がるごとにリスクが1.01倍になる。
性別(sex):
HR = 0.58。女性は男性に比べて、イベントのリスクが約0.6倍低い。
まとめ
この記事では、AIエディタでRを動かすことで、論文でよく使われる生存時間解析をRで簡単に実践するプロセスをご紹介しました。結果のTableや綺麗なFigureの出力まで、論文や学会発表に必要なものは全てコードを書かずに作成することができました。

